删除历史已被发布数据
This commit is contained in:
parent
ba09fb2865
commit
4d564918e1
@ -1,181 +0,0 @@
|
||||
---
|
||||
id: "2018-10-20-10-38-05"
|
||||
date: "2018/10/20 10:38:05"
|
||||
title: "spring基础"
|
||||
tags: ["java", "spring"]
|
||||
categories:
|
||||
- "java"
|
||||
- "spring学习"
|
||||
---
|
||||
|
||||
  spring 是为了解决企业级应用开发的复杂性而创建的,spring 最根本的使命是:简化 Java 开发。为降低开发复杂性有以下四种关键策略。
|
||||
|
||||
- 基于 POJO 的轻量级和最小侵入性编程
|
||||
- 通过依赖注入和面向接口实现松耦合
|
||||
- 基于切面和惯例进行声明式编程
|
||||
- 通过切面和模板减少样板式代码
|
||||
|
||||
#### 1.依赖注入
|
||||
|
||||
  假设类 A 依赖类 B,通常做法是在类 A 中声明类 B,然后使用,这样一方面具有极高的耦合性,将类 A 与类 B 绑定在一起;另一方面也让单元测试变得很困难,无法在 A 外部获得 B 的执行情况。
|
||||
|
||||
  通过依赖注入,对象的依赖管理将不用对象本身来管理,将由一个第三方组件在创建对象时设定,依赖关系将被自动注入到对应的对象中去。
|
||||
|
||||
#### 2.创建应用上下文
|
||||
|
||||
- `ClassPathXmlApplicationContext()`从类路径创建
|
||||
- `FileSystemXmlApplicationContext()`读取文件系统下的 xml 配置
|
||||
- `XmlWebApplicationContext()` 读取 web 应用下的 XML 配置文件并装载上下文定义
|
||||
|
||||
#### 3.声明 Bean
|
||||
|
||||
<!-- more -->
|
||||
|
||||
1. 最简单
|
||||
|
||||
`<bean id="bean1" class="com.example.Class"/>`
|
||||
|
||||
2. 带构造器
|
||||
|
||||
```xml
|
||||
<bean id="bean1" class="com.example.Class">
|
||||
<contructor-arg value="12"/> //基本数据类型使用value
|
||||
<contructor-arg ref="bean2"/> //对象使用ref
|
||||
</bean>
|
||||
```
|
||||
|
||||
3. 通过工厂方法创建
|
||||
|
||||
如果想声明的 Bean 没有一个公开的构造函数,通过 factory-method 属性来装配工厂生产的 Bean
|
||||
|
||||
```xml
|
||||
<bean id="bean1" class="com.example.class" factory-method="getInstance"/>//getInstance为获取实例的静态方法。
|
||||
```
|
||||
|
||||
#### 4.Bean 的作用域
|
||||
|
||||
所有 Spring Bean 默认都是单例的。通过配置 scope 属性为 prototype 可每次请求产生一个新的实例。
|
||||
|
||||
```xml
|
||||
<bean id="bean3" class="com.example.class" scope="prototype">
|
||||
```
|
||||
|
||||
scope 可选值:
|
||||
|
||||
- `singleton`:每个容器中,一个 Bean 对象只有一个实例。(**默认**)
|
||||
- `prototype`:允许实例化任意次 ,每次请求都会创建新的
|
||||
- `request`:作用域为一次 http 请求
|
||||
- `session`:作用域为一个 http session 会话
|
||||
- `global-session`:作用域为一个全局 http session,仅在 Protlet 上下文中有效
|
||||
|
||||
#### 5.初始化和销毁 Bean
|
||||
|
||||
当实例化需要执行初始化操作,或者销毁时需要执行清理工作。两种实现方式:
|
||||
|
||||
1. xml 配置,类中编写初始化方法和销毁方法,在 bean 中定义。
|
||||
|
||||
```xml
|
||||
<bean id="bean4" class="com.example.Class" init-method="start" destroy-method="destroy"/>
|
||||
```
|
||||
|
||||
也可在 Beans 中定义默认初始化和销毁方法。
|
||||
|
||||
```xml
|
||||
<beans . . . default-init-method="" default-destroy-method=""/>
|
||||
```
|
||||
|
||||
2. 实现`InitializingBean`和`DisposableBean`接口
|
||||
|
||||
#### 6.setter 注入
|
||||
|
||||
在 bean 中使用`<property>`元素配置属性,使用方法类似于`<constructor-arg>`
|
||||
|
||||
```xml
|
||||
<property name="name" value="fxg"/> //注入基本数据类型
|
||||
<property name="sex" ref="sex"/> //注入类
|
||||
```
|
||||
|
||||
可使用 p 简写,**-ref**后缀说明装配的是一个引用
|
||||
|
||||
```xml
|
||||
<bean id="bean5" class="com.example.class"
|
||||
p:name="fxb"
|
||||
p:sex-ref="sex"/>
|
||||
```
|
||||
|
||||
#### 7.注入内部 Bean
|
||||
|
||||
既定义其他 Bean 内部的 Bean,避免共享问题,可在属性节点或者构造器参数节点上使用。
|
||||
|
||||
```xml
|
||||
<property name="sex">
|
||||
<bean class="com.example.sex"/> //没有id属性,因为不会被其他bean使用
|
||||
</property>
|
||||
<constructor-arg>
|
||||
<bean class="com.example.sex"/>
|
||||
</constructor-arg>
|
||||
```
|
||||
|
||||
#### 8.装配集合
|
||||
|
||||
| 集合元素 | 用途 |
|
||||
| --------- | -------------------------------- |
|
||||
| \<list\> | 装配 list 类型,允许重复 |
|
||||
| \<set\> | set,不能重复 |
|
||||
| \<map\> | map 类型 |
|
||||
| \<props\> | properties 类型,键值都为 String |
|
||||
|
||||
- list
|
||||
|
||||
```xml
|
||||
<property name="instruments">
|
||||
<list>
|
||||
<ref bean="guitar"/>
|
||||
<ref bean="cymbal"/>
|
||||
<ref bean="harmonica"/>
|
||||
</list>
|
||||
</property>
|
||||
<ref>用来定义上下文中的其他引用,还可使用<value>,<bean>,<null/>
|
||||
```
|
||||
|
||||
- set
|
||||
|
||||
```xml
|
||||
<set>
|
||||
<ref bean="fasdf"/>
|
||||
</set>
|
||||
```
|
||||
|
||||
用法和 list 相同,只是不能重复
|
||||
|
||||
- Map
|
||||
|
||||
```XML
|
||||
<map>
|
||||
<entry key="GUITAR" value-ref="guitar"/>
|
||||
</map>
|
||||
```
|
||||
|
||||
entry 元素由一个 key,一个 value 组成,分别有两种形式。
|
||||
|
||||
| key | 键为 String |
|
||||
| :-------- | ---------------- |
|
||||
| key-ref | 键为 Bean 的引用 |
|
||||
| value | 值为 String |
|
||||
| value-ref | 值为 Bean 的引用 |
|
||||
|
||||
- props
|
||||
|
||||
```xml
|
||||
<props>
|
||||
<prop key="GUITAR">guitar</prop>
|
||||
</props>
|
||||
```
|
||||
|
||||
键值都是 String
|
||||
|
||||
#### 9.装配空值
|
||||
|
||||
```xml
|
||||
<property name="name"><null/></property>
|
||||
```
|
||||
@ -1,235 +0,0 @@
|
||||
---
|
||||
id: "2018-10-21-10-38-05"
|
||||
date: "2018/10/21 10:38:05"
|
||||
title: "spring之最小化XML配置"
|
||||
tags: ["java", "spring"]
|
||||
categories:
|
||||
- "java"
|
||||
- "spring学习"
|
||||
---
|
||||
|
||||
## 一、自动装配
|
||||
|
||||
### 1、四种类型的自动装配
|
||||
|
||||
| 类型 | 解释 | xml 配置 |
|
||||
| ---------- | -------------------------------------- | ---------------------------------------------- |
|
||||
| byName | 根据 Bean 的 name 或者 id | \<bean id="bean" class="…" autowire="byName"/> |
|
||||
| ByType | 根据 Bean 类型自动装配 | \<bean id="bean" class="…" autowire="byType"/> |
|
||||
| contructor | 根据 Bean 的构造器入参具有相同类型 | 同上 |
|
||||
| Autodetect | 首先使用 contructor,失败再尝试 byType | 同上 |
|
||||
|
||||
  byType 在出现多个匹配项时不会自动选择一个然是报错,为避免报错,有两种办法:1.使用\<bean>元素的 primary 属性,设置为首选 Bean,但所有 bean 的默认 primary 都是 true,因此我们需要将所有非首选 Bean 设置为**false**;2.将 Bean 的`autowire-candidate`熟悉设置为**false**,取消 这个 Bean 的候选资格,这个 Bean 便不会自动注入了。
|
||||
|
||||
  contructor 自动装配和 byType 有一样的局限性,当发现多个 Bean 匹配某个构造器入参时,Spring 不会尝试选择其中一个;此外,如果一个类有多个构造器都满足自动装配的条件,Spring 也不会猜测哪个更合适使用。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
### 2、默认自动装配
|
||||
|
||||
  如果需要为 Spring 应用上下文中的每个 Bean(或者其中的大多数)配置相同的 autowire 属性,可以在根元素\<beans>上增加一个 default-autowire 属性,默认该属性设置为 none。该属性只应用于指定配置文件中的所有 Bean,并不是 Spring 上下文中的所有 Bean。
|
||||
|
||||
### 3、混合使用自动装配和显式装配
|
||||
|
||||
  当我们对某个 Bean 使用了自动装配策略,并不代表我们不能对该 Bean 的某些属性进行显示装配,任然可以为任意一个属性配置\<property>元素,显式装配将会覆盖自动装配。**但是**当使用 constructor 自动装配策略时,我们必须让 Spring 自动装配构造器所有入参,不能使用\<constructor-arg>元素进行混合。
|
||||
|
||||
## 二、注解装配
|
||||
|
||||
  从 Spring2.5 开始,可以使用注解自动装配 Bean 的属性,使用注解允许更细粒度的自动装配,可选择性的标注某一个属性来对其应用自动装配。Spring 容器默认禁用注解装配,需要在 Spring 配置中启用,最简单的启用方式是使用 Spring 的 context 命令空间配置中的`<context:annotation-config>`,如下所示:
|
||||
|
||||
```xml
|
||||
<beans ...>
|
||||
<context:annotation-config/>
|
||||
<!-- bean declarations go here -->
|
||||
</beans>
|
||||
```
|
||||
|
||||
  Spring3 支持几种不同的用于自动装配的注解:
|
||||
|
||||
- Spring 自带的@Autowired 注解
|
||||
- JSR-330 的@Inject 注解
|
||||
- JSR-250 的@Resource 注解
|
||||
|
||||
### 1、使用@Autowired
|
||||
|
||||
  @Autowired 用于对被注解对象启动 ByType 的自动装配,可用于以下对象:
|
||||
|
||||
- 类属性,即使私有属性也能注入
|
||||
- set 方法
|
||||
- 构造器
|
||||
- 任意需要装配 Bean 的方法
|
||||
|
||||
在使用@Autowired 时有两种情况会出错:没有匹配的 Bean 和存在多个匹配的 Bean,但是都有对应的解决方法。
|
||||
|
||||
- 当没有匹配 Bean 时,自动装配会抛出 NoSuchBeanDefinitionException,如果不想抛出可使用 required 属性,设置为 false 来配置可选的自动装配,即装配失败就不进行装配,不会报错。
|
||||
|
||||
```java
|
||||
@Autowired(required=false)
|
||||
```
|
||||
|
||||
当使用构造器配置时,只有一个构造器可以将 required 属性设置为 true,其他都只能设置为 false。此外,当使用注解标注多个构造器时,Spring 会从所有满足装配条件的构造器中选择入参最多的那个。
|
||||
|
||||
- 当存在多个 Bean 满足装配条件时,Spring 也会抛出 NoSuchBeanDefinitionException 错误,为了选择指定的 Bean,我们可以使用@Qualifier 注解进行筛选:
|
||||
|
||||
```java
|
||||
@Autowired
|
||||
@Qualifier("name1")//筛选名为name1的Bean
|
||||
private TestClass testClass;
|
||||
```
|
||||
|
||||
除了通过 Bean 的 ID 来缩小选择范围,我们还可以通过直接在 Bean 上使用 qualifier 来缩小范围,限制 Bean 的类型,xml 如下:
|
||||
|
||||
```xml
|
||||
<bean class="com.test.xxx">
|
||||
<qualifier value="stringed"/>
|
||||
</bean>
|
||||
```
|
||||
|
||||
注解如下:
|
||||
|
||||
```java
|
||||
@Qualifier("stringed")
|
||||
public class xxx{}
|
||||
```
|
||||
|
||||
还可以创建**自定义限定器(Qualifier)**
|
||||
|
||||
  创建自定义限定器只需要使用@Qualifier 注解作为它的源注解即可,如下创建了一个 Stringed 限定器:
|
||||
|
||||
```java
|
||||
@Target({ElementType.FIELD,ElementType.PARAMETER,ElementType.TYPE})
|
||||
@Retention(RetentionPolicy.RUNTIME)
|
||||
@Qualifier
|
||||
public @interface Stringed{}
|
||||
```
|
||||
|
||||
然后使用它注解一个 Bean:
|
||||
|
||||
```java
|
||||
@Stringed
|
||||
public class Guitar{}
|
||||
```
|
||||
|
||||
然后就可以进行限定了:
|
||||
|
||||
```java
|
||||
@Autowired
|
||||
@Stringed
|
||||
private Guitar guitar;
|
||||
```
|
||||
|
||||
### 2、使用@Inject 自动注入
|
||||
|
||||
  为统一各种依赖注入框架的编程模型,JCP(Java Community Process)发布的 Java 依赖注入规范,被称为 JSR-330,从 Spring3 开始,Spring 已经开始兼容该依赖注入模型。
|
||||
|
||||
  和@Autowired 一样,@Inject 可以用来自动装配属性、方法和构造器。但是@Inject 没有 required 属性,因此依赖关系必须存在,如不存在将抛出异常。
|
||||
|
||||
  JSR-330 还提供另一种注入技巧,注入一个 Provider。Provider 接口可以实现 Bean 引用的延迟注入以及注入 Bean 的多个实例等功能。
|
||||
|
||||
  例如我们有一个 KnifeJuggler 类需要注入一个或多个 Knife 实例,假设 Knife Bean 的作用域声明为 prototype,下面的 KnifeJuggler 的构造器将获得多个 Knife Bean:
|
||||
|
||||
```java
|
||||
private Set<Knife> knifes;
|
||||
|
||||
@Inject
|
||||
public KnifeJuggler(Provider<Knife> knifeProvider){
|
||||
knives = new HashSet<Knife>();
|
||||
for(int i=0;i<5;i++){
|
||||
knives.add(knifeProvider.get());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
  相对于@Autowired 所对应的@Qualifier,@Inject 对应的是@Named 注解。事实上 JSR-330 中也有@Qualifier 注解,不过不建议直接使用,建议通过该注解来创建自定义的限定注解,和 Spring 的@Qualifier 创建过程类似。
|
||||
|
||||
### 3、注解中使用表达式
|
||||
|
||||
  Spring3 中引入的`@Value`属性可用来装配 String 类型的值和基本类型的值。借助 SpEL 表达式,@Value 不光可以装配硬编码值还可以在运行期动态计算表达式并装配,例如下面的:
|
||||
|
||||
```java
|
||||
@Value("#{systemProperties.name}")
|
||||
private String name;
|
||||
```
|
||||
|
||||
## 三、自动检测 Bean
|
||||
|
||||
  在 Spring 中使用上面说到的`<context:annotation-config>`,可以做到自动装配,但还是要在 xml 中申明 Bean。Spring 还有另一个元素`<context:component-scan>`,元素除了完成自动装配的功能,还允许 Spring 自动检测 Bean 和定义 Bean ,用法如下:
|
||||
|
||||
```xml
|
||||
<beans ...>
|
||||
<context:component-scan base-package="com.springtest">
|
||||
</context:component-scan>
|
||||
</beans>
|
||||
```
|
||||
|
||||
开启后支持如下注解:
|
||||
|
||||
| 注解 | 解释 |
|
||||
| ----------- | -------------------------------------- |
|
||||
| @Component | 通用的构造型注解,标识类为 Spring 组件 |
|
||||
| @Controller | 标识该类定义为 Spring MVC controller |
|
||||
| @Repository | 标识该类定义为数据仓库 |
|
||||
| @Service | 标识该类定义为服务 |
|
||||
|
||||
  使用上述注解是 Bean 的 ID 默认为无限定类名。使用`@Component("name")`指定 ID。
|
||||
|
||||
### 1、过滤组建扫描
|
||||
|
||||
  通过为\<context:component-scan>配置<context:include-filter>和<context:exclude-filter>子元素,我们可以随意调整扫描行为。下面的配置自动注册所有的 TestInterface 实现类:
|
||||
|
||||
```xml
|
||||
<context:component-scan base-package="com.fxb.springtest">
|
||||
<context:include-filter type="assignable"
|
||||
expression="com.fxb.springTest.TestInterface"/>
|
||||
</context:component-scan>
|
||||
```
|
||||
|
||||
其中的 type 和 expression 属性一起协作来定义组件扫描策略。type 有以下值可选择:
|
||||
|
||||
| 过滤器类型 | 描述 |
|
||||
| ---------- | ---------------------------------------------------------------------------------------- |
|
||||
| annotation | 过滤器扫描使用指定注解所标注的类。通过 expression 属性指定要扫描的注解 |
|
||||
| assignable | 过滤器扫描派生于 expression 属性所指定类型的那些类 |
|
||||
| aspectj | 过滤器扫描于 expression 属性所指定的 AspectJ 表达式所匹配的那些类 |
|
||||
| custom | 使用自定义的 org.springframework.core.type.TypeFilter 实现类,该类由 expression 属性指定 |
|
||||
| regex | 过滤器扫描类的名称与 expression 属性所指定的正则表达式所匹配的类 |
|
||||
|
||||
  exclude-filter 使用和 include-filter 类似,只是效果相反。
|
||||
|
||||
## 四、使用 Spring 基于 Java 的配置
|
||||
|
||||
  在 Spring3.0 中几乎可以不使用 XML 而使用纯粹的 Java 代码来配置 Spring 应用。
|
||||
|
||||
- 首先还是需要极少量的 XML 来启用 Java 配置,就是上面说到的`<context:component-scan>`,该标签还会自动加载使用`@Configuration`注解所标识的类
|
||||
|
||||
- @Configuration 注解相当于 XML 配置中的\<beans>元素,这个注解将会告知 Spring:这个类包含一个或多个 Spring Bean 的定义,这些定义是使用@Bean 注解所标注的方法
|
||||
|
||||
- 申明一个简单的 Bean 代码如下:
|
||||
|
||||
```java
|
||||
@Configuration
|
||||
public class TestConfig{
|
||||
@Bean
|
||||
public Animal duck(){
|
||||
return new Ducker();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
@Bean 告知 Spring 这个方法将返回一个对象,该对象应该被注册为 Spring 应用上下文中的一个 Bean,方法名作为该 Bean 的 ID 。想要使用另一个 Bean 的引用也很简单,如下:
|
||||
|
||||
```java
|
||||
@Bean
|
||||
public Food duckFood(){
|
||||
return new DuckFood();
|
||||
}
|
||||
|
||||
@Bean //通过方法名引用一个Bean,并不会创建一个新的实例
|
||||
public Animal duck(){
|
||||
return new Ducker(DuckFood());
|
||||
}
|
||||
```
|
||||
|
||||
## 五、小结
|
||||
|
||||
  终于写完了 spring 的最小化配置,对 spring 的各种注解也有了一些了解,再不是之前看到注解一脸莫名其妙了,虽然现在 Springboot 已经帮我们做了零 XML 配置,但觉得还是有必要了解下 XML 配置实现,这样对 Java 的配置实现理解也会更加深刻。
|
||||
@ -1,248 +0,0 @@
|
||||
---
|
||||
id: "2018-10-22-10-38-05"
|
||||
date: "2018/10/22 10:38:05"
|
||||
title: "spring之面向切面"
|
||||
tags: ["java", "spring"]
|
||||
categories:
|
||||
- "java"
|
||||
- "spring学习"
|
||||
---
|
||||
|
||||
  Spring 的基础是 IOC 和 AOP,前面两节对 IOC 和 DI 做了简单总结,这里再对 AOP 进行一个学习总结,Spring 基础就算有一个初步了解了。
|
||||
|
||||
## 一.面向切面编程
|
||||
|
||||
  在软件开发中,我们可能需要一些跟业务无关但是又必须做的东西,比如日志,事务等,这些分布于应用中多处的功能被称为横切关注点,通常横切关注点从概念上是与应用的业务逻辑相分离的。如何将这些横切关注点与业务逻辑在代码层面进行分离,是面向切面编程(**AOP**)所要解决的。
|
||||
|
||||
横切关注点可以被描述为影响应用多处的功能,切面能够帮助我们模块化横切关注点。下图直观呈现了横切关注点的概念:
|
||||
|
||||
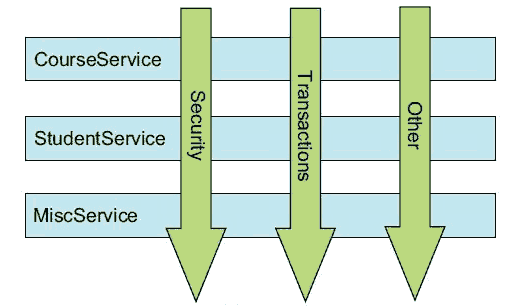
|
||||
|
||||
图中 CourseService,StudentService,MiscService 都需要类似安全、事务这样的辅助功能,这些辅助功能就被称为横切关注点。
|
||||
|
||||
  **继承**和**委托**是最常见的实现重用通用功能的面向对象技术。但是如果在整个程序中使用相同的基类继承往往会导致一个脆弱的对象体系;而使用委托可能需要对委托对象进行复杂的调用。
|
||||
|
||||
  切面提供了取代继承和委托的另一种选择,而且更加清晰简洁。在面向切面编程时,我们任然在一个地方定义通用功能,但是我们可以通过声明的方式定义这个功能以何种方式在何处应用,而无需修改受影响的类,受影响类完全感受不到切面的存在。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
## 二.AOP 常用术语
|
||||
|
||||
  下面是 AOP 中常用的名词。
|
||||
|
||||
### 1. 通知(Advice)
|
||||
|
||||
  通知定义了切面是什么以及何时使用。出了描述切面要完成的工作,通知还解决了何时执行这个工作的问题。Sping 切面可以应用以下 5 种类型的通知。
|
||||
|
||||
- **Before** 在方法被调用之前调用通知
|
||||
- **After** 在方法完成之后调用通知,无论方法执行是否成功
|
||||
- **After-returning** 在方法成功执行后调用通知
|
||||
- **After-throwing** 在方法抛出异常后调用通知
|
||||
- **Around** 通知包裹了被通知的方法,在被通知的方法调用前和调用后执行
|
||||
|
||||
###2.连接点(Joinpoint)
|
||||
|
||||
  应用可能有很多个时机应用通知,这些时机被称为连接点。连接点是应用在执行过程中能够插入切面的一个点,这个点可以是调用方法时、抛出异常时、甚至是修改字段时。切面代码可以利用这些切入到应用的正常流程中,并添加新的行为。
|
||||
|
||||
### 3.切点(Pointcut)
|
||||
|
||||
  切点定义了通知所要织入的一个或多个连接点。如果说通知定义了切面的“**什么**”和“**何时**”,那么切点就定义了“**何处**”。通常使用明确的类和方法名称来指定切点,或者利用正则表达式定义匹配的类和方法来指定这些切点。有些 AOP 框架允许我们创建动态的切点,可以更具运行时的策略来决定是否应用通知。
|
||||
|
||||
### 4.切面(Aspect)
|
||||
|
||||
  切面是通知和切点的结合。通知和切点定义了关于切面的全部内容,**是什么**,在**何时**、**何处**完成其功能。
|
||||
|
||||
### 5.引入
|
||||
|
||||
  引入允许我们想现有的类添加新方法或属性。即在无需修改现有类的情况下让它们具有新的行为和状态。
|
||||
|
||||
### 6.织入
|
||||
|
||||
  织入是将切面应用到目标对象来创建新的代理对象的过程。切面在指定的连接点被织入到目标对象中,在目标对象的生命周期里有多个点可以进行织入。
|
||||
|
||||
- 编译期:切面在目标类编译时被织入。这种方式需要特殊的编译期,比如 AspectJ 的织入编译期
|
||||
- 类加载期:切面在目标类加载到 JVM 时被织入。这种方式需要特殊的加载器,它可以在目标类被引入应用之前增强该目标类的字节码,例如 AspectJ5 的**LTW**(load-time weaving)
|
||||
- 运行期:切面在应用运行的某个时刻被织入。一般情况下 AOP 容器会为目标对象动态创建一个代理对象
|
||||
|
||||
##三.Spring AOP
|
||||
|
||||
  Spring 在运行期通知对象,通过在代理类中包裹切面,Spring 在运行期将切面织入到 Spring 管理的 Bean 中。代理类封装了目标类,并拦截被通知的方法的调用,再将调用转发给真正的目标 Bean。由于 Spring 是基于动态代理,所有 Spring 只支持方法连接点,如果需要方法拦截之外的连接点拦截,我们可以利用 Aspect 来协助 SpringAOP。
|
||||
|
||||
  Spring 在运行期通知对象,通过在代理类中包裹切面,Spring 在运行期将切面织入到 Spring 管理的 Bean 中。代理类封装了目标类,并拦截被通知的方法的调用,再将调用转发给真正的目标 Bean。由于 Spring 是基于动态代理,所有 Spring 只支持方法连接点,如果需要方法拦截之外的连接点拦截,我们可以利用 Aspect 来协助 SpringAOP。
|
||||
|
||||
### 1、定义切点
|
||||
|
||||
  在 SpringAOP 中,需要使用 AspectJ 的切点表达式语言来定义切点。Spring 只支持 AspectJ 的部分切点指示器,如下表所示:
|
||||
|
||||
| AspectJ 指示器 | 描述 |
|
||||
| -------------- | --------------------------------------------------------------------------------------------- |
|
||||
| arg() | 限制连接点匹配参数为指定类型的执行方法 |
|
||||
| @args() | 限制连接点匹配参数由指定注解标注的执行方法 |
|
||||
| execution() | 用于匹配是连接点的执行方法 |
|
||||
| this() | 限制连接点匹配 AOP 代理的 Bean 引用为指导类型的类 |
|
||||
| target() | 限制连接点匹配目标对象为指定类型的类 |
|
||||
| @target() | 限制连接点匹配特定的执行对象,这些对象对应的类要具备指定类型的注解 |
|
||||
| within() | 限制连接点匹配指定的类型 |
|
||||
| @within() | 限制连接点匹配指定注解所标注的类型(当使用 SpringAOP 时,方法定义在由指定的注解所标注的类里) |
|
||||
| @annotation | 限制匹配带有指定注解连接点 |
|
||||
| bean() | 使用 Bean ID 或 Bean 名称作为参数来限制切点只匹配特定的 Bean |
|
||||
|
||||
 其中只有 execution 指示器是唯一的执行匹配,其他都是限制匹配。因此 execution 指示器是
|
||||
|
||||
其中只有 execution 指示器是唯一的执行匹配,其他都是限制匹配。因此 execution 指示器是我们在编写切点定义时最主要使用的指示器。
|
||||
|
||||
### 2、编写切点
|
||||
|
||||
  假设我们要使用 execution()指示器选择 Hello 类的 sayHello()方法,表达式如下:
|
||||
|
||||
```java
|
||||
execution(* com.test.Hello.sayHello(..))
|
||||
```
|
||||
|
||||
方法表达式以**\* **号开始,说明不管方法返回值的类型。然后指定全限定类名和方法名。对于方法参数列表,我们使用(\*\*)标识切点选择任意的 sayHello()方法,无论方法入参是什么。
|
||||
|
||||
  同时我们可以使用 (and),||(or),!(not)来连接指示器,如下所示:
|
||||
|
||||
```java
|
||||
execution(* com.test.Hello.sayHello(..)) and !bean(xiaobu)
|
||||
```
|
||||
|
||||
### 3、申明切面
|
||||
|
||||
  在经典 Spring AOP 中使用 ProxyFactoryBean 非常复杂,因此提供了申明式切面的选择,在 Spring 的 AOP 配置命名空间中有如下配置元素:
|
||||
|
||||
| AOP 配置元素 | 描述 |
|
||||
| ------------------------------ | -------------------------------------------------------------- |
|
||||
| <aop:advisor > | 定义 AOP 通知器 |
|
||||
| <aop:after > | 定义 AOP 后置通知(无论被通知方法是否执行成功) |
|
||||
| <aop:after-returning > | 定义 AOP after-returning 通知 |
|
||||
| <aop:after-throwing > | 定义 after-throwing |
|
||||
| <aop:around > | 定义 AOP 环绕通知 |
|
||||
| <aop:aspect > | 定义切面 |
|
||||
| <aop:aspectj-autoproxy > | 启用@AspectJ 注解驱动的切面 |
|
||||
| <aop:before > | 定义 AOP 前置通知 |
|
||||
| <aop:config > | 顶层的 AOP 配置元素。大多数的<aop:\* >元素必须包含在其中 |
|
||||
| <aop:declare-parents > | 为被通知的对象引入额外的接口,并透明的实现 |
|
||||
| <aop:pointcut > | 定义切点 |
|
||||
|
||||
### 4、实现
|
||||
|
||||
假设有一个演员类`Actor`,演员类中有一个表演方法`perform()`,然后还有一个观众类`Audience`,这两个类都在包`com.example.springtest`下,Audience 类主要方法如下:
|
||||
|
||||
```java
|
||||
public class Audience{
|
||||
//搬凳子
|
||||
public void takeSeats(){}
|
||||
//欢呼
|
||||
public void applaud(){}
|
||||
//计时,环绕通知需要一个ProceedingJoinPoint参数
|
||||
public void timing(ProceedingJoinPoint joinPoint){
|
||||
joinPoint.proceed();
|
||||
}
|
||||
//演砸了
|
||||
public void demandRefund(){}
|
||||
//测试带参数
|
||||
public void dealString(String word){}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
#### a、xml 配置实现
|
||||
|
||||
  首先将 Audience 配置到 springIOC 中:
|
||||
|
||||
```xml
|
||||
<bean id="audience" class="com.example.springtest.Audience"/>
|
||||
```
|
||||
|
||||
然后申明通知:
|
||||
|
||||
```xml
|
||||
<aop:config>
|
||||
<aop:aspect ref="audience">
|
||||
<!-- 申明切点 -->
|
||||
<aop:pointcut id="performance" expression="execution(* com.example.springtest.Performer.perform(..))"/>
|
||||
<!-- 声明传递参数切点 -->
|
||||
<aop:pointcut id="performanceStr" expression="execution(* com.example.springtest.Performer.performArg(String) and args(word))"/>
|
||||
<!-- 前置通知 -->
|
||||
<aop:before pointcut-ref="performance" method="takeSeats"/>
|
||||
<!-- 执行成功通知 -->
|
||||
<aop:after-returning pointcout-ref="performance" method="applaud"/>
|
||||
<!-- 执行异常通知 -->
|
||||
<aop:after-throwing pointcut-ref="performance" method="demandRefund"/>
|
||||
<!-- 环绕通知 -->
|
||||
<aop:around pointcut-ref="performance" method="timing"/>
|
||||
<!-- 传递参数 -->
|
||||
<aop:before pointcut-ref="performanceStr" arg-names="word" method="dealString"/>
|
||||
</aop:aspect>
|
||||
</aop:config>
|
||||
```
|
||||
|
||||
#### b、注解实现
|
||||
|
||||
直接在 Audience 类上加注解(Aspect 注解并不能被 spring 自动发现并注册,要么写到 xml 中,要么使用@Aspectj 注解或者加一个@Component 注解),如下所示:
|
||||
|
||||
```java
|
||||
@Aspect
|
||||
public class Audience{
|
||||
//定义切点
|
||||
@Pointcut(execution(* com.example.springtest.Performer.perform(..)))
|
||||
public void perform(){}
|
||||
|
||||
//定义带参数切点
|
||||
@Pointcut(execution(* com.example.springtest.Performer.performArg(String) and args(word)))
|
||||
public void performStr(String word){}
|
||||
|
||||
//搬凳子
|
||||
@Before("perform()")
|
||||
public void takeSeats(){}
|
||||
|
||||
//欢呼
|
||||
@AfterReturning("perform()")
|
||||
public void applaud(){}
|
||||
|
||||
//计时,环绕通知需要一个ProceedingJoinPoint参数
|
||||
@Around("perform()")
|
||||
public void timing(ProceedingJoinPoint joinPoint){
|
||||
joinPoint.proceed();
|
||||
}
|
||||
|
||||
//演砸了
|
||||
@AfterThrowing("perform()")
|
||||
public void demandRefund(){}
|
||||
|
||||
//带参数
|
||||
@Before("performStr(word)")
|
||||
public void dealString(String word){}
|
||||
}
|
||||
```
|
||||
|
||||
#### c、通过切面引入新功能
|
||||
|
||||
  既然可以用 AOP 为对象拥有的方法添加新功能,那为什么不能为对象增加新的方法呢?利用被称为**引入**的 AOP 概念,切面可以为 Spring Bean 添加新的方法,示例图如下:
|
||||
|
||||
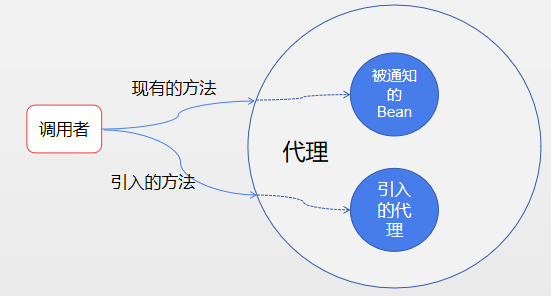
|
||||
|
||||
当引入接口的方法被调用时,代理将此调用委托给实现了新接口的某个其他对象。实际上,Bean 的实现被拆分到了多个类。
|
||||
|
||||
- xml 引入需要使用<aop:declare-parents >元素:
|
||||
|
||||
```xml
|
||||
<aop:aspect>
|
||||
<aop:declare-parents types-matching="com.fxb.springtest.Performer+"
|
||||
implement-interface="com.fxb.springtest.AddTestInterface"
|
||||
default-impl="com.fxb.springtest.AddTestImpl"/>
|
||||
</aop:aspect>
|
||||
```
|
||||
|
||||
顾名思义\<declare-parents>声明了此切面所通知的 Bean 在它的对象层次结构中有了新的父类型。其中 types-matching 指定增强的类;implement-interface 指定实现新方法的接口;default-imple 指定实现了 implement-interface 接口的实现类,也可以用 delegate-ref 来指定一个 Bean 的引用。
|
||||
|
||||
- 注解引入,通过`@DeclareParents`注解
|
||||
|
||||
```xml
|
||||
@DeclareParents(value="com.fxb.springtest.Performer+",
|
||||
defaultImpl=AddTestImpl.class)
|
||||
public static AddTestInterface addTestInterface;
|
||||
```
|
||||
|
||||
同 xml 实现一样,注解也由三部分组成:1、value 属性相当于 tpes-matching 属性,标识被增强的类;2、defaultImpl 等同于 default-imple,指定接口的实现类;3、有@DeclareParents 注解所标注的 static 属性指定了将被引入的接口。
|
||||
@ -1,60 +0,0 @@
|
||||
---
|
||||
id: "2018-08-13-10-38"
|
||||
date: "2018/08/13 10:38:00"
|
||||
title: "springboot搭建"
|
||||
tags: ["java", "spring","springboot","idea"]
|
||||
categories:
|
||||
- "java"
|
||||
- "spring boot学习"
|
||||
---
|
||||
|
||||
  前面的博客有说到 spring boot 搭建见另一篇博文,其实那篇博文还没写,现在来填个坑。我们使用 spring initializr 来构建,idea 和 eclipse 都支持这种方式,构建过程类似,这里以 idea 为例,详细记录构建过程。
|
||||
|
||||
### 1.选择 spring initializr
|
||||
|
||||
|
||||
|
||||
next
|
||||
|
||||
#### 2.设置参数
|
||||
|
||||
|
||||
|
||||
next
|
||||
|
||||
#### 3.选择依赖
|
||||
|
||||
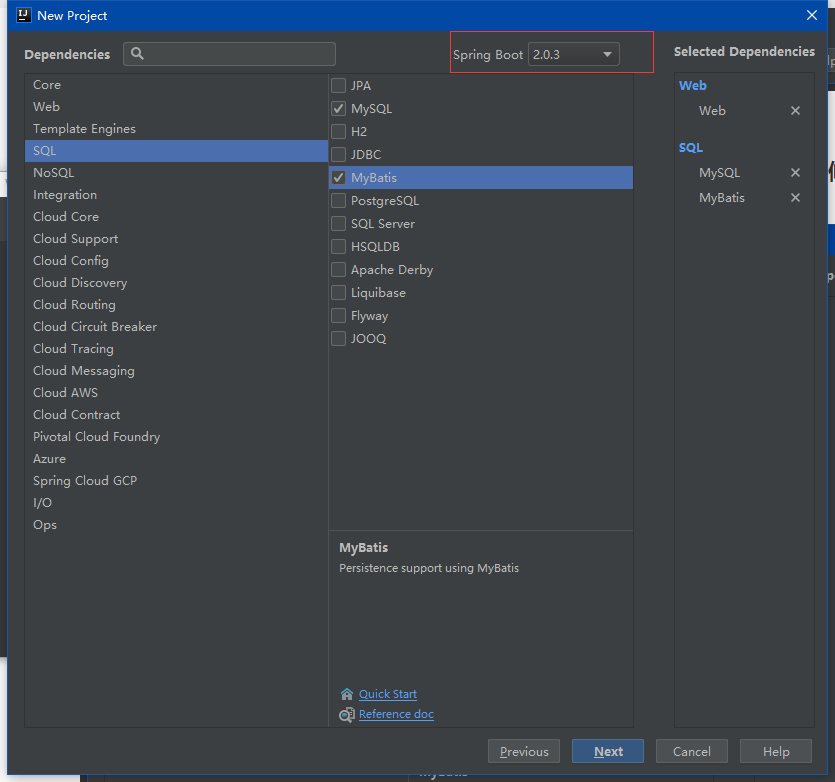
  在这里选择 spring boot 版本和 web 依赖(忽略 sql 的依赖,如有需要[点击这里](f),单独将 mybatis 的整合),后面也可手动编辑 pom 文件修改增加删除依赖
|
||||
|
||||
|
||||
|
||||
这里我们选择 web 搭建一个简单的 REST 风格 demo。然后 next。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
#### 4.设置项目存放地址
|
||||
|
||||
|
||||
|
||||
这样就成功构建了一个 springboot 项目。
|
||||
|
||||
#### 5.测试
|
||||
|
||||
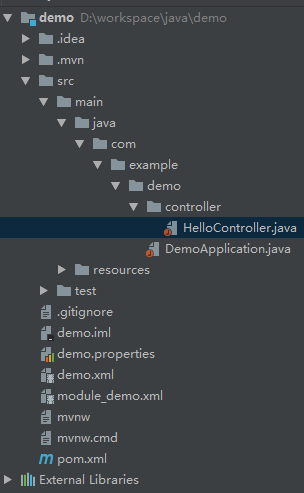
  现在新建一个 controller 包,包下新建一个 HelloController,创建之后项目目录结构如下:
|
||||
|
||||
|
||||
|
||||
HelloController 代码如下:
|
||||
|
||||
```java
|
||||
@RestController
|
||||
@RequestMapping("/home")
|
||||
public class HelloController{
|
||||
@GetMapping("/hello")
|
||||
public String sayHello(){
|
||||
return "hello";
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
然后运行项目,访问 [localhost:8080/home/hello](localhost:8080/home/hello) 即可看到 hello 字符串。
|
||||
@ -1,289 +0,0 @@
|
||||
---
|
||||
id: "2018-08-20-10-38"
|
||||
date: "2018/08/20 10:38:00"
|
||||
title: "springboot+security整合(1)"
|
||||
tags: ["java", "spring","springboot","spring-security","security"]
|
||||
categories:
|
||||
- "java"
|
||||
- "spring boot学习"
|
||||
---
|
||||
|
||||
**说明 springboot 版本 2.0.3<br/>源码地址:[点击跳转](https://github.com/FleyX/demo-project/tree/master/springboot_spirngsecurity_demo)**
|
||||
|
||||
## 一、 介绍
|
||||
|
||||
  Spring Security 是一个能够为基于 Spring 的企业应用系统提供声明式的安全访问控制解决方案的安全框架。它提供了一组可以在 Spring 应用上下文中配置的 Bean,充分利用了 Spring IoC,DI(控制反转 Inversion of Control ,DI:Dependency Injection 依赖注入)和 AOP(面向切面编程)功能,为应用系统提供声明式的安全访问控制功能,减少了为企业系统安全控制编写大量重复代码的工作。
|
||||
|
||||
## 二、 环境搭建
|
||||
|
||||
  建立 springboot2 项目,加入 security 依赖,mybatis 依赖
|
||||
|
||||
<!-- more -->
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-security</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.mybatis.spring.boot</groupId>
|
||||
<artifactId>mybatis-spring-boot-starter</artifactId>
|
||||
<version>1.3.2</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>mysql</groupId>
|
||||
<artifactId>mysql-connector-java</artifactId>
|
||||
<scope>runtime</scope>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
数据库为传统的用户--角色--权限,权限表记录了 url 和 method,springboot 配置文件如下:
|
||||
|
||||
```yml
|
||||
mybatis:
|
||||
type-aliases-package: com.example.demo.entity
|
||||
server:
|
||||
port: 8081
|
||||
spring:
|
||||
datasource:
|
||||
driver-class-name: com.mysql.jdbc.Driver
|
||||
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true
|
||||
username: root
|
||||
password: 123456
|
||||
http:
|
||||
encoding:
|
||||
charset: utf-8
|
||||
enabled: true
|
||||
```
|
||||
|
||||
springboot 启动类中加入如下代码,设置路由匹配规则。
|
||||
|
||||
```java
|
||||
@Override
|
||||
protected void configurePathMatch(PathMatchConfigurer configurer) {
|
||||
configurer.setUseSuffixPatternMatch(false) //设置路由是否后缀匹配,譬如/user能够匹配/user.,/user.aa
|
||||
.setUseTrailingSlashMatch(false); //设置是否后缀路径匹配,比如/user能够匹配/user,/user/
|
||||
}
|
||||
```
|
||||
|
||||
## 三、 security 配置
|
||||
|
||||
  默认情况下 security 是无需任何自定义配置就可使用的,我们不考虑这种方式,直接讲如何个性化登录过程。
|
||||
|
||||
#### 1、 建立 security 配置文件,目前配置文件中还没有任何配置。
|
||||
|
||||
```java
|
||||
@Configuration
|
||||
public class SecurityConfig extends WebSecurityConfigurerAdapter {
|
||||
}
|
||||
```
|
||||
|
||||
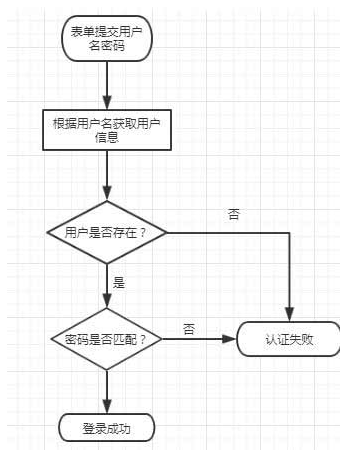
#### 2、 个性化登录,security 中的登录如下:
|
||||
|
||||
|
||||
|
||||
- security 需要一个 user 的实体类实现`UserDetails`接口,该实体类最后与系统中用户的实体类分开,代码如下:
|
||||
|
||||
```java
|
||||
public class SecurityUser implements UserDetails{
|
||||
private static final long serialVersionUID = 1L;
|
||||
private String password;
|
||||
private String name;
|
||||
List<GrantedAuthority> authorities;
|
||||
|
||||
public SecurityUser(string name,string password) {
|
||||
this.id = id;
|
||||
this.password = password;
|
||||
this.name = name;
|
||||
this.age = age;
|
||||
}
|
||||
|
||||
public void setAuthorities(List<GrantedAuthority> authorities) {
|
||||
this.authorities = authorities;
|
||||
}
|
||||
|
||||
@Override
|
||||
public Collection<GrantedAuthority> getAuthorities() {
|
||||
return this.authorities;
|
||||
}
|
||||
|
||||
@Override //获取校验用户名
|
||||
public String getUsername() {
|
||||
return String.valueOf(this.id);
|
||||
}
|
||||
|
||||
@Override //获取校验用密码
|
||||
public String getPassword() {
|
||||
return password;
|
||||
}
|
||||
|
||||
@Override //账户是否未过期
|
||||
public boolean isAccountNonExpired() {
|
||||
// TODO Auto-generated method stub
|
||||
return true;
|
||||
}
|
||||
|
||||
@Override //账户是否未锁定
|
||||
public boolean isAccountNonLocked() {
|
||||
// TODO Auto-generated method stub
|
||||
return true;
|
||||
}
|
||||
|
||||
@Override //帐户密码是否未过期,一般有的密码要求性高的系统会使用到,比较每隔一段时间就要求用户重置密码
|
||||
public boolean isCredentialsNonExpired() {
|
||||
// TODO Auto-generated method stub
|
||||
return true;
|
||||
}
|
||||
|
||||
@Override //账户是否可用
|
||||
public boolean isEnabled() {
|
||||
// TODO Auto-generated method stub
|
||||
return true;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
- 编写了实体类还需要编写一个服务类 SecurityService 实现`UserDetailsService`接口,重写 loadByUsername 方法,通过这个方法根据用户名获取用户信息,代码如下:
|
||||
|
||||
```java
|
||||
@Component
|
||||
public class SecurityUserService implements UserDetailsService {
|
||||
@Autowired
|
||||
private JurisdictionMapper jurisdictionMapper;
|
||||
@Autowired
|
||||
private UserMapper userMapper;
|
||||
private Logger log = LoggerFactory.getLogger(this.getClass());
|
||||
|
||||
|
||||
@Override
|
||||
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
|
||||
log.info("登录用户id为:{}",username);
|
||||
int id = Integer.valueOf(username);
|
||||
User user = userMapper.getById(id);
|
||||
if(user==null) {
|
||||
//抛出错误,用户不存在
|
||||
throw new UsernameNotFoundException("用户名 "+username+"不存在");
|
||||
}
|
||||
//获取用户权限
|
||||
List<GrantedAuthority> authorities = new ArrayList<>();
|
||||
List<Jurisdiction> jurisdictions = jurisdictionMapper.selectByUserId(id);
|
||||
for(Jurisdiction item : jurisdictions) {
|
||||
GrantedAuthority authority = new MyGrantedAuthority(item.getMethod(),item.getUrl());
|
||||
authorities.add(authority);
|
||||
}
|
||||
SecurityUser securityUser = new SecurityUser(user.getName(),user.getPassword(),authority):
|
||||
user.setAuthorities(authorities);
|
||||
return securityUser;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
- 通常我们会对密码进行加密,所有还要编写一个 passwordencode 类,实现 PasswordEncoder 接口,代码如下:
|
||||
|
||||
```java
|
||||
@Component
|
||||
public class MyPasswordEncoder implements PasswordEncoder {
|
||||
private Logger log = LoggerFactory.getLogger(this.getClass());
|
||||
|
||||
@Override //不清楚除了在下面方法用到还有什么用处
|
||||
public String encode(CharSequence rawPassword) {
|
||||
return StringUtil.StringToMD5(rawPassword.toString());
|
||||
}
|
||||
|
||||
//判断密码是否匹配
|
||||
@Override
|
||||
public boolean matches(CharSequence rawPassword, String encodedPassword) {
|
||||
return encodedPassword.equals(this.encode(rawPassword));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 3、 编辑配置文件
|
||||
|
||||
- 编写 config Bean 以使用上面定义的验证逻辑,securityUserService、myPasswordEncoder 通过@Autowired 引入。
|
||||
|
||||
```java
|
||||
@Override
|
||||
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
|
||||
auth.userDetailsService(securityUserService)
|
||||
.passwordEncoder(myPasswordEncoder);
|
||||
}
|
||||
```
|
||||
|
||||
- 然后编写 configure Bean(和上一个不一样,参数不同),实现 security 验证逻辑,代码如下:
|
||||
|
||||
```java
|
||||
@Override
|
||||
protected void configure(HttpSecurity http) throws Exception {
|
||||
http
|
||||
.csrf() //跨站
|
||||
.disable() //关闭跨站检测
|
||||
.authorizeRequests()//验证策略策略链
|
||||
.antMatchers("/public/**").permitAll()//无需验证路径
|
||||
.antMatchers("/login").permitAll()//放行登录
|
||||
.antMatchers(HttpMethod.GET, "/user").hasAuthority("getAllUser")//拥有权限才可访问
|
||||
.antMatchers(HttpMethod.GET, "/user").hasAnyAuthority("1","2")//拥有任一权限即可访问
|
||||
//角色类似,hasRole(),hasAnyRole()
|
||||
.anyRequest().authenticated()
|
||||
.and()
|
||||
.formLogin()
|
||||
.loginPage("/public/unlogin") //未登录跳转页面,设置了authenticationentrypoint后无需设置未登录跳转页面
|
||||
.loginProcessingUrl("/public/login")//处理登录post请求接口,无需自己实现
|
||||
.successForwardUrl("/success")//登录成功转发接口
|
||||
.failureForwardUrl("/failed")//登录失败转发接口
|
||||
.usernameParameter("id") //修改用户名的表单name,默认为username
|
||||
.passwordParameter("password")//修改密码的表单name,默认为password
|
||||
.and()
|
||||
.logout()//自定义登出
|
||||
.logoutUrl("/public/logout") //自定义登出api,无需自己实现
|
||||
.logoutSuccessUrl("public/logoutSuccess")
|
||||
}
|
||||
```
|
||||
|
||||
到这里便可实现 security 与 springboot 的基本整合。
|
||||
|
||||
## 四、实现记住我功能
|
||||
|
||||
#### 1、 建表
|
||||
|
||||
  记住我功能需要数据库配合实现,首先要在数据库建一张表用户保存 cookie 和用户名,数据库建表语句如下:不能做修改
|
||||
|
||||
```sql
|
||||
CREATE TABLE `persistent_logins` (
|
||||
`username` varchar(64) NOT NULL,
|
||||
`series` varchar(64) NOT NULL,
|
||||
`token` varchar(64) NOT NULL,
|
||||
`last_used` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
|
||||
PRIMARY KEY (`series`)
|
||||
)
|
||||
```
|
||||
|
||||
#### 2、 编写 rememberMeservice Bean
|
||||
|
||||
  代码如下:
|
||||
|
||||
```java
|
||||
@Bean
|
||||
public RememberMeServices rememberMeServices(){
|
||||
JdbcTokenRepositoryImpl jdbcTokenRepository = new JdbcTokenRepositoryImpl();
|
||||
jdbcTokenRepository.setDataSource(dataSource);
|
||||
PersistentTokenBasedRememberMeServices rememberMeServices =
|
||||
new PersistentTokenBasedRememberMeServices("INTERNAL_SECRET_KEY",securityUserService,jdbcTokenRepository);
|
||||
//还可设置许多其他属性
|
||||
rememberMeServices.setCookieName("kkkkk"); //客户端cookie名
|
||||
return rememberMeServices;
|
||||
}
|
||||
```
|
||||
|
||||
dataSource 为@Autowired 引入
|
||||
|
||||
#### 3、 配置文件设置 remember
|
||||
|
||||
  在 config(HttpSecurity http)中加入记住我功能
|
||||
|
||||
```java
|
||||
.rememberMe()
|
||||
.rememberMeServices(rememberMeServices())
|
||||
.key("INTERNAL_SECRET_KEY")
|
||||
```
|
||||
|
||||
在登录表单中设置 remember-me 即可实现记住我功能。
|
||||
@ -1,106 +0,0 @@
|
||||
---
|
||||
id: "2018-08-21-10-38"
|
||||
date: "2018/08/21 10:38"
|
||||
title: "springboot+security整合(2)"
|
||||
tags: ["java", "spring","springboot","spring-security","security"]
|
||||
categories:
|
||||
- "java"
|
||||
- "spring boot学习"
|
||||
---
|
||||
|
||||
  紧接着上一篇,上一篇中登录验证都由 security 帮助我们完成了,如果我们想要增加一个验证码登录或者其它的自定义校验就没办法了,因此这一篇讲解如何实现这个功能。
|
||||
|
||||
##一、 实现自定义登录校验类
|
||||
|
||||
  继承 UsernamePasswordAuthenticationFilter 类来拓展登录校验,代码如下:
|
||||
|
||||
```java
|
||||
public class MyUsernamePasswordAuthentication extends UsernamePasswordAuthenticationFilter{
|
||||
|
||||
private Logger log = LoggerFactory.getLogger(this.getClass());
|
||||
|
||||
@Override
|
||||
public Authentication attemptAuthentication(HttpServletRequest request, HttpServletResponse response)
|
||||
throws AuthenticationException {
|
||||
//我们可以在这里进行额外的验证,如果验证失败抛出继承AuthenticationException的自定义错误。
|
||||
log.info("在这里进行验证码判断");
|
||||
//只要最终的验证是账号密码形式就无需修改后续过程
|
||||
return super.attemptAuthentication(request, response);
|
||||
}
|
||||
|
||||
@Override
|
||||
public void setAuthenticationManager(AuthenticationManager authenticationManager) {
|
||||
// TODO Auto-generated method stub
|
||||
super.setAuthenticationManager(authenticationManager);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
<!-- more -->
|
||||
|
||||
##二、 将自定义登录配置到 security 中
|
||||
  编写自定义登录过滤器后,configure Bean 修改为如下:
|
||||
|
||||
```java
|
||||
@Override
|
||||
protected void configure(HttpSecurity http) throws Exception {
|
||||
http
|
||||
.csrf() //跨站
|
||||
.disable() //关闭跨站检测
|
||||
//自定义鉴权过程,无需下面设置
|
||||
.authorizeRequests()//验证策略
|
||||
.antMatchers("/public/**").permitAll()//无需验证路径
|
||||
.antMatchers("/user/**").permitAll()
|
||||
.antMatchers("/login").permitAll()//放行登录
|
||||
.antMatchers(HttpMethod.GET, "/user").hasAuthority("getAllUser")//拥有权限才可访问
|
||||
.antMatchers(HttpMethod.GET, "/user").hasAnyAuthority("1","2")//拥有任一权限即可访问
|
||||
//角色类似,hasRole(),hasAnyRole()
|
||||
.anyRequest().authenticated()
|
||||
.and()
|
||||
//自定义异常处理
|
||||
.exceptionHandling()
|
||||
.authenticationEntryPoint(myAuthenticationEntryPoint)//未登录处理
|
||||
.accessDeniedHandler(myAccessDeniedHandler)//权限不足处理
|
||||
.and()
|
||||
//加入自定义登录校验
|
||||
.addFilterBefore(myUsernamePasswordAuthentication(),UsernamePasswordAuthenticationFilter.class)
|
||||
.rememberMe()//默认放在内存中
|
||||
.rememberMeServices(rememberMeServices())
|
||||
.key("INTERNAL_SECRET_KEY")
|
||||
// 重写usernamepasswordauthenticationFilter后,下面的formLogin()设置将失效,需要手动设置到个性化过滤器中
|
||||
// .and()
|
||||
// .formLogin()
|
||||
// .loginPage("/public/unlogin") //未登录跳转页面,设置了authenticationentrypoint后无需设置未登录跳转页面
|
||||
// .loginProcessingUrl("/public/login")//登录api
|
||||
// .successForwardUrl("/success")
|
||||
// .failureForwardUrl("/failed")
|
||||
// .usernameParameter("id")
|
||||
// .passwordParameter("password")
|
||||
// .failureHandler(myAuthFailedHandle) //登录失败处理
|
||||
// .successHandler(myAuthSuccessHandle)//登录成功处理
|
||||
// .usernameParameter("id")
|
||||
.and()
|
||||
.logout()//自定义登出
|
||||
.logoutUrl("/public/logout")
|
||||
.logoutSuccessUrl("public/logoutSuccess")
|
||||
.logoutSuccessHandler(myLogoutSuccessHandle);
|
||||
}
|
||||
```
|
||||
|
||||
然后再编写 Bean,代码如下:
|
||||
|
||||
```java
|
||||
@Bean
|
||||
public MyUsernamePasswordAuthentication myUsernamePasswordAuthentication(){
|
||||
MyUsernamePasswordAuthentication myUsernamePasswordAuthentication = new MyUsernamePasswordAuthentication();
|
||||
myUsernamePasswordAuthentication.setAuthenticationFailureHandler(myAuthFailedHandle); //设置登录失败处理类
|
||||
myUsernamePasswordAuthentication.setAuthenticationSuccessHandler(myAuthSuccessHandle);//设置登录成功处理类
|
||||
myUsernamePasswordAuthentication.setFilterProcessesUrl("/public/login");
|
||||
myUsernamePasswordAuthentication.setRememberMeServices(rememberMeServices()); //设置记住我
|
||||
myUsernamePasswordAuthentication.setUsernameParameter("id");
|
||||
myUsernamePasswordAuthentication.setPasswordParameter("password");
|
||||
return myUsernamePasswordAuthentication;
|
||||
}
|
||||
```
|
||||
|
||||
完成。
|
||||
@ -1,239 +0,0 @@
|
||||
---
|
||||
id: "2018-08-22-10-38"
|
||||
date: "2018/08/22 10:38:00"
|
||||
title: "springboot+security整合(3)"
|
||||
tags: ["java", "spring", "springboot", "spring-security", "security"]
|
||||
categories:
|
||||
- "java"
|
||||
- "spring boot学习"
|
||||
---
|
||||
|
||||
  这篇讲解如何自定义鉴权过程,实现根据数据库查询出的 url 和 method 是否匹配当前请求的 url 和 method 来决定有没有权限。security 鉴权过程如下:
|
||||
|
||||
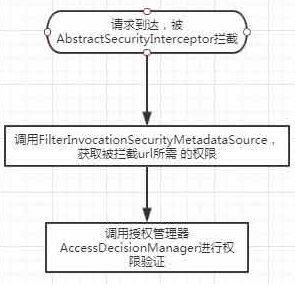
|
||||
|
||||
## 一、 重写 metadataSource 类
|
||||
|
||||
1. 编写 MyGranteAuthority 类,让权限包含 url 和 method 两个部分。
|
||||
|
||||
```java
|
||||
public class MyGrantedAuthority implements GrantedAuthority {
|
||||
private String method;
|
||||
private String url;
|
||||
|
||||
public MyGrantedAuthority(String method, String url) {
|
||||
this.method = method;
|
||||
this.url = url;
|
||||
}
|
||||
|
||||
@Override
|
||||
public String getAuthority() {
|
||||
return url;
|
||||
}
|
||||
|
||||
public String getMethod() {
|
||||
return method;
|
||||
}
|
||||
|
||||
public String getUrl() {
|
||||
return url;
|
||||
}
|
||||
|
||||
@Override
|
||||
public boolean equals(Object obj) {
|
||||
if(this==obj) return true;
|
||||
if(obj==null||getClass()!= obj.getClass()) return false;
|
||||
MyGrantedAuthority grantedAuthority = (MyGrantedAuthority)obj;
|
||||
if(this.method.equals(grantedAuthority.getMethod())&&this.url.equals(grantedAuthority.getUrl()))
|
||||
return true;
|
||||
return false;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
2. 编写 MyConfigAttribute 类,实现 ConfigAttribute 接口,代码如下:
|
||||
|
||||
<!-- more -->
|
||||
|
||||
```java
|
||||
public class MyConfigAttribute implements ConfigAttribute {
|
||||
private HttpServletRequest httpServletRequest;
|
||||
private MyGrantedAuthority myGrantedAuthority;
|
||||
|
||||
public MyConfigAttribute(HttpServletRequest httpServletRequest) {
|
||||
this.httpServletRequest = httpServletRequest;
|
||||
}
|
||||
|
||||
public MyConfigAttribute(HttpServletRequest httpServletRequest, MyGrantedAuthority myGrantedAuthority) {
|
||||
this.httpServletRequest = httpServletRequest;
|
||||
this.myGrantedAuthority = myGrantedAuthority;
|
||||
}
|
||||
|
||||
public HttpServletRequest getHttpServletRequest() {
|
||||
return httpServletRequest;
|
||||
}
|
||||
|
||||
@Override
|
||||
public String getAttribute() {
|
||||
return myGrantedAuthority.getUrl();
|
||||
}
|
||||
|
||||
public MyGrantedAuthority getMyGrantedAuthority() {
|
||||
return myGrantedAuthority;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
3. 编写 MySecurityMetadataSource 类,获取当前 url 所需要的权限
|
||||
|
||||
```java
|
||||
@Component
|
||||
public class MySecurityMetadataSource implements FilterInvocationSecurityMetadataSource {
|
||||
|
||||
private Logger log = LoggerFactory.getLogger(this.getClass());
|
||||
|
||||
@Autowired
|
||||
private JurisdictionMapper jurisdictionMapper;
|
||||
private List<Jurisdiction> jurisdictions;
|
||||
|
||||
private void loadResource() {
|
||||
this.jurisdictions = jurisdictionMapper.selectAllPermission();
|
||||
}
|
||||
|
||||
|
||||
@Override
|
||||
public Collection<ConfigAttribute> getAttributes(Object object) throws IllegalArgumentException {
|
||||
if (jurisdictions == null) this.loadResource();
|
||||
HttpServletRequest request = ((FilterInvocation) object).getRequest();
|
||||
Set<ConfigAttribute> allConfigAttribute = new HashSet<>();
|
||||
AntPathRequestMatcher matcher;
|
||||
for (Jurisdiction jurisdiction : jurisdictions) {
|
||||
//使用AntPathRequestMatcher比较可让url支持ant风格,例如/user/*/a
|
||||
//*匹配一个或多个字符,**匹配任意字符或目录
|
||||
matcher = new AntPathRequestMatcher(jurisdiction.getUrl(), jurisdiction.getMethod());
|
||||
if (matcher.matches(request)) {
|
||||
ConfigAttribute configAttribute = new MyConfigAttribute(request,new MyGrantedAuthority(jurisdiction.getMethod(),jurisdiction.getUrl()));
|
||||
allConfigAttribute.add(configAttribute);
|
||||
//这里是获取到一个权限就返回,根据校验规则也可获取多个然后返回
|
||||
return allConfigAttribute;
|
||||
}
|
||||
}
|
||||
//未匹配到,说明无需权限验证
|
||||
return null;
|
||||
}
|
||||
|
||||
@Override
|
||||
public Collection<ConfigAttribute> getAllConfigAttributes() {
|
||||
return null;
|
||||
}
|
||||
|
||||
@Override
|
||||
public boolean supports(Class<?> clazz) {
|
||||
return FilterInvocation.class.isAssignableFrom(clazz);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 二、 编写 MyAccessDecisionManager 类
|
||||
|
||||
  实现 AccessDecisionManager 接口以实现权限判断,直接 return 说明验证通过,如不通过需要抛出对应错误,代码如下:
|
||||
|
||||
```java
|
||||
@Component
|
||||
public class MyAccessDecisionManager implements AccessDecisionManager{
|
||||
private Logger log = LoggerFactory.getLogger(this.getClass());
|
||||
|
||||
@Override
|
||||
public void decide(Authentication authentication, Object object, Collection<ConfigAttribute> configAttributes)
|
||||
throws AccessDeniedException, InsufficientAuthenticationException {
|
||||
//无需验证放行
|
||||
if(configAttributes==null || configAttributes.size()==0)
|
||||
return;
|
||||
if(!authentication.isAuthenticated()){
|
||||
throw new InsufficientAuthenticationException("未登录");
|
||||
}
|
||||
Collection<? extends GrantedAuthority> authorities = authentication.getAuthorities();
|
||||
for(ConfigAttribute attribute : configAttributes){
|
||||
MyConfigAttribute urlConfigAttribute = (MyConfigAttribute)attribute;
|
||||
for(GrantedAuthority authority: authorities){
|
||||
MyGrantedAuthority myGrantedAuthority = (MyGrantedAuthority)authority;
|
||||
if(urlConfigAttribute.getMyGrantedAuthority().equals(myGrantedAuthority))
|
||||
return;
|
||||
}
|
||||
}
|
||||
throw new AccessDeniedException("无权限");
|
||||
}
|
||||
|
||||
@Override
|
||||
public boolean supports(ConfigAttribute attribute) {
|
||||
return true;
|
||||
}
|
||||
|
||||
@Override
|
||||
public boolean supports(Class<?> clazz) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 三、 编写 MyFilterSecurityInterceptor 类
|
||||
|
||||
  该类继承 AbstractSecurityInterceptor 类,实现 Filter 接口,代码如下:
|
||||
|
||||
```java
|
||||
@Component
|
||||
public class MyFilterSecurityInterceptor extends AbstractSecurityInterceptor implements Filter {
|
||||
|
||||
//注入上面编写的两个类
|
||||
@Autowired
|
||||
private MySecurityMetadataSource mySecurityMetadataSource;
|
||||
|
||||
@Autowired
|
||||
public void setMyAccessDecisionManager(MyAccessDecisionManager myAccessDecisionManager) {
|
||||
super.setAccessDecisionManager(myAccessDecisionManager);
|
||||
}
|
||||
|
||||
@Override
|
||||
public void init(FilterConfig arg0) throws ServletException {
|
||||
}
|
||||
|
||||
|
||||
@Override
|
||||
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
|
||||
FilterInvocation fi = new FilterInvocation(request, response, chain);
|
||||
invoke(fi);
|
||||
}
|
||||
|
||||
public void invoke(FilterInvocation fi) throws IOException, ServletException {
|
||||
//这里进行权限验证
|
||||
InterceptorStatusToken token = super.beforeInvocation(fi);
|
||||
try {
|
||||
fi.getChain().doFilter(fi.getRequest(), fi.getResponse());
|
||||
} finally {
|
||||
super.afterInvocation(token, null);
|
||||
}
|
||||
}
|
||||
|
||||
@Override
|
||||
public void destroy() {
|
||||
}
|
||||
|
||||
@Override
|
||||
public Class<?> getSecureObjectClass() {
|
||||
return FilterInvocation.class;
|
||||
}
|
||||
|
||||
@Override
|
||||
public SecurityMetadataSource obtainSecurityMetadataSource() {
|
||||
return this.mySecurityMetadataSource;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 四、 加入到 security 的过滤器链中
|
||||
|
||||
```java
|
||||
.addFilterBefore(urlFilterSecurityInterceptor,FilterSecurityInterceptor.class)
|
||||
```
|
||||
|
||||
完成
|
||||
@ -1,224 +0,0 @@
|
||||
---
|
||||
id: "2018-08-25-10-38"
|
||||
date: "2018/08/25 10:38:00"
|
||||
title: "springboot整合WebSocket"
|
||||
tags: ["java", "spring","springboot","WebSocket"]
|
||||
categories:
|
||||
- "java"
|
||||
- "spring boot学习"
|
||||
---
|
||||
|
||||
### 一、背景
|
||||
|
||||
  我们都知道 http 协议只能浏览器单方面向服务器发起请求获得响应,服务器不能主动向浏览器推送消息。想要实现浏览器的主动推送有两种主流实现方式:
|
||||
|
||||
- 轮询:缺点很多,但是实现简单
|
||||
- websocket:在浏览器和服务器之间建立 tcp 连接,实现全双工通信
|
||||
|
||||
  springboot 使用 websocket 有两种方式,一种是实现简单的 websocket,另外一种是实现**STOMP**协议。这一篇实现简单的 websocket,STOMP 下一篇在讲。
|
||||
|
||||
**注意:如下都是针对使用 springboot 内置容器**
|
||||
|
||||
### 二、实现
|
||||
|
||||
#### 1、依赖引入
|
||||
|
||||
  要使用 websocket 关键是`@ServerEndpoint`这个注解,该注解是 javaee 标准中的注解,tomcat7 及以上已经实现了,如果使用传统方法将 war 包部署到 tomcat 中,只需要引入如下 javaee 标准依赖即可:
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>javax</groupId>
|
||||
<artifactId>javaee-api</artifactId>
|
||||
<version>7.0</version>
|
||||
<scope>provided</scope>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
如使用 springboot 内置容器,无需引入,springboot 已经做了包含。我们只需引入如下依赖即可:
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-websocket</artifactId>
|
||||
<version>1.5.3.RELEASE</version>
|
||||
<type>pom</type>
|
||||
</dependency>
|
||||
```
|
||||
<!-- more -->
|
||||
|
||||
#### 2、注入 Bean
|
||||
|
||||
  首先注入一个**ServerEndpointExporter**Bean,该 Bean 会自动注册使用@ServerEndpoint 注解申明的 websocket endpoint。代码如下:
|
||||
|
||||
```java
|
||||
@Configuration
|
||||
public class WebSocketConfig {
|
||||
@Bean
|
||||
public ServerEndpointExporter serverEndpointExporter(){
|
||||
return new ServerEndpointExporter();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 3、申明 endpoint
|
||||
|
||||
  建立**MyWebSocket.java**类,在该类中处理 websocket 逻辑
|
||||
|
||||
```java
|
||||
@ServerEndpoint(value = "/websocket") //接受websocket请求路径
|
||||
@Component //注册到spring容器中
|
||||
public class MyWebSocket {
|
||||
|
||||
|
||||
//保存所有在线socket连接
|
||||
private static Map<String,MyWebSocket> webSocketMap = new LinkedHashMap<>();
|
||||
|
||||
//记录当前在线数目
|
||||
private static int count=0;
|
||||
|
||||
//当前连接(每个websocket连入都会创建一个MyWebSocket实例
|
||||
private Session session;
|
||||
|
||||
private Logger log = LoggerFactory.getLogger(this.getClass());
|
||||
//处理连接建立
|
||||
@OnOpen
|
||||
public void onOpen(Session session){
|
||||
this.session=session;
|
||||
webSocketMap.put(session.getId(),this);
|
||||
addCount();
|
||||
log.info("新的连接加入:{}",session.getId());
|
||||
}
|
||||
|
||||
//接受消息
|
||||
@OnMessage
|
||||
public void onMessage(String message,Session session){
|
||||
log.info("收到客户端{}消息:{}",session.getId(),message);
|
||||
try{
|
||||
this.sendMessage("收到消息:"+message);
|
||||
}catch (Exception e){
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
|
||||
//处理错误
|
||||
@OnError
|
||||
public void onError(Throwable error,Session session){
|
||||
log.info("发生错误{},{}",session.getId(),error.getMessage());
|
||||
}
|
||||
|
||||
//处理连接关闭
|
||||
@OnClose
|
||||
public void onClose(){
|
||||
webSocketMap.remove(this.session.getId());
|
||||
reduceCount();
|
||||
log.info("连接关闭:{}",this.session.getId());
|
||||
}
|
||||
|
||||
//群发消息
|
||||
|
||||
//发送消息
|
||||
public void sendMessage(String message) throws IOException {
|
||||
this.session.getBasicRemote().sendText(message);
|
||||
}
|
||||
|
||||
//广播消息
|
||||
public static void broadcast(){
|
||||
MyWebSocket.webSocketMap.forEach((k,v)->{
|
||||
try{
|
||||
v.sendMessage("这是一条测试广播");
|
||||
}catch (Exception e){
|
||||
}
|
||||
});
|
||||
}
|
||||
|
||||
//获取在线连接数目
|
||||
public static int getCount(){
|
||||
return count;
|
||||
}
|
||||
|
||||
//操作count,使用synchronized确保线程安全
|
||||
public static synchronized void addCount(){
|
||||
MyWebSocket.count++;
|
||||
}
|
||||
|
||||
public static synchronized void reduceCount(){
|
||||
MyWebSocket.count--;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 4、客户的实现
|
||||
|
||||
  客户端使用 h5 原生 websocket,部分浏览器可能不支持。代码如下:
|
||||
|
||||
```html
|
||||
<html>
|
||||
<head>
|
||||
<title>websocket测试</title>
|
||||
<meta charset="utf-8" />
|
||||
</head>
|
||||
|
||||
<body>
|
||||
<button onclick="sendMessage()">测试</button>
|
||||
<script>
|
||||
let socket = new WebSocket('ws://localhost:8080/websocket');
|
||||
socket.onerror = err => {
|
||||
console.log(err);
|
||||
};
|
||||
socket.onopen = event => {
|
||||
console.log(event);
|
||||
};
|
||||
socket.onmessage = mess => {
|
||||
console.log(mess);
|
||||
};
|
||||
socket.onclose = () => {
|
||||
console.log('连接关闭');
|
||||
};
|
||||
|
||||
function sendMessage() {
|
||||
if (socket.readyState === 1) socket.send('这是一个测试数据');
|
||||
else alert('尚未建立websocket连接');
|
||||
}
|
||||
</script>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
### 三、测试
|
||||
|
||||
  建立一个 controller 测试群发,代码如下:
|
||||
|
||||
```java
|
||||
@RestController
|
||||
public class HomeController {
|
||||
|
||||
@GetMapping("/broadcast")
|
||||
public void broadcast(){
|
||||
MyWebSocket.broadcast();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
然后打开上面的 html,可以看到浏览器和服务器都输出连接成功的信息:
|
||||
|
||||
```
|
||||
浏览器:
|
||||
Event {isTrusted: true, type: "open", target: WebSocket, currentTarget: WebSocket, eventPhase: 2, …}
|
||||
|
||||
服务端:
|
||||
2018-08-01 14:05:34.727 INFO 12708 --- [nio-8080-exec-1] com.fxb.h5websocket.MyWebSocket : 新的连接加入:0
|
||||
```
|
||||
|
||||
点击测试按钮,可在服务端看到如下输出:
|
||||
|
||||
```
|
||||
2018-08-01 15:00:34.644 INFO 12708 --- [nio-8080-exec-6] com.fxb.h5websocket.MyWebSocket : 收到客户端2消息:这是一个测试数据
|
||||
```
|
||||
|
||||
再次打开 html 页面,这样就有两个 websocket 客户端,然后在浏览器访问[localhost:8080/broadcast](localhost:8080/broadcast)测试群发功能,每个客户端都会输出如下信息:
|
||||
|
||||
```
|
||||
MessageEvent {isTrusted: true, data: "这是一条测试广播", origin: "ws://localhost:8080", lastEventId: "", source: null, …}
|
||||
```
|
||||
|
||||
  源码可在 [github 下载](https://github.com/FleyX/demo-project/tree/master/h5websocket) 上下载,记得点赞,star 哦
|
||||
@ -1,368 +0,0 @@
|
||||
---
|
||||
id: "2018-09-01-10-38"
|
||||
date: "2018/09/01 10:38:00"
|
||||
title: "springboot整合Mybatis(xml和注解)"
|
||||
tag: ["java", "spring","springboot","mysql","mybatis","xml","注解"]
|
||||
categories:
|
||||
- "java"
|
||||
- "spring boot学习"
|
||||
---
|
||||
|
||||
## 写在前面
|
||||
|
||||
  项目源代码在 github,地址为:[https://github.com/FleyX/demo-project/tree/master/mybatis-test](https://github.com/FleyX/demo-project/tree/master/mybatis-test),有需要的自取。
|
||||
|
||||
  刚毕业的第一份工作是 java 开发,项目中需要用到 mybatis,特此记录学习过程,这只是一个简单 demo,mybatis 用法很多不可能全部写出来,有更复杂的需求建议查看 mybatis 的官方中文文档,[点击跳转](http://www.mybatis.org/mybatis-3/zh/index.html)。下面时项目环境/版本。
|
||||
|
||||
- 开发工具:IDEA
|
||||
- jdk 版本:1.8
|
||||
- springboot 版本:2.03
|
||||
|
||||
其他依赖版本见下面 pom.xml:
|
||||
|
||||
<!-- more -->
|
||||
|
||||
```xml
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
|
||||
<modelVersion>4.0.0</modelVersion>
|
||||
|
||||
<groupId>com.example</groupId>
|
||||
<artifactId>mybatis-test</artifactId>
|
||||
<version>0.0.1-SNAPSHOT</version>
|
||||
<packaging>jar</packaging>
|
||||
|
||||
<name>mybatis-test</name>
|
||||
<description>Demo project for Spring Boot</description>
|
||||
|
||||
<parent>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-parent</artifactId>
|
||||
<version>2.0.3.RELEASE</version>
|
||||
<relativePath/> <!-- lookup parent from repository -->
|
||||
</parent>
|
||||
|
||||
<properties>
|
||||
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
|
||||
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
|
||||
<java.version>1.8</java.version>
|
||||
</properties>
|
||||
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-web</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>mysql</groupId>
|
||||
<artifactId>mysql-connector-java</artifactId>
|
||||
<scope>runtime</scope>
|
||||
</dependency>
|
||||
<!--mybatis依赖 -->
|
||||
<dependency>
|
||||
<groupId>org.mybatis.spring.boot</groupId>
|
||||
<artifactId>mybatis-spring-boot-starter</artifactId>
|
||||
<version>1.3.2</version>
|
||||
</dependency>
|
||||
<!--alibaba连接池依赖-->
|
||||
<dependency>
|
||||
<groupId>com.alibaba</groupId>
|
||||
<artifactId>druid-spring-boot-starter</artifactId>
|
||||
<version>1.1.9</version>
|
||||
</dependency>
|
||||
<!--分页依赖-->
|
||||
<dependency>
|
||||
<groupId>com.github.pagehelper</groupId>
|
||||
<artifactId>pagehelper-spring-boot-starter</artifactId>
|
||||
<version>1.2.5</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-test</artifactId>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
|
||||
<build>
|
||||
<plugins>
|
||||
<plugin>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-maven-plugin</artifactId>
|
||||
</plugin>
|
||||
</plugins>
|
||||
</build>
|
||||
</project>
|
||||
```
|
||||
|
||||
## 1.创建项目
|
||||
|
||||
使用 idea 中的 spring initializr 生成 maven 项目,项目命令为 mybatis-test,选择 web,mysql,mybatis 依赖,即可成功。(详细过程不赘述,如有需要学习 springboot 创建过程,可参考[这篇文章](http://tapme.top/blog/detail/2018-08-13-10-38)。
|
||||
|
||||
然后依照上面的 pom 文件,补齐缺少的依赖。接着创建包 entity,service 和 mybatis 映射文件夹 mapper,创建。为了方便配置将 application.properties 改成 application.yml。由于我们时 REST 接口,故不需要 static 和 templates 目录。修改完毕后的项目结构如下:
|
||||
|
||||
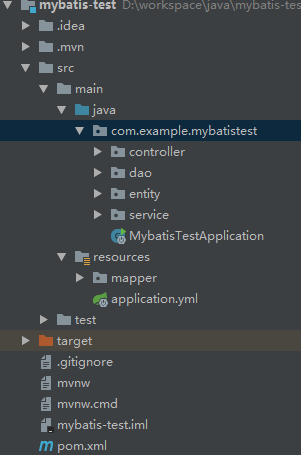
|
||||
|
||||
  修改启动类,增加`@MapperScan("com.example.mybatistest.dao")`,以自动扫描 dao 目录,避免每个 dao 都手动加`@Mapper`注解。代码如下:
|
||||
|
||||
```java
|
||||
@SpringBootApplication
|
||||
@MapperScan("com.example.mybatistest.dao")
|
||||
public class MybatisTestApplication {
|
||||
public static void main(String[] args) {
|
||||
SpringApplication.run(MybatisTestApplication.class, args);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
修改 application.yml,配置项目,代码如下:
|
||||
|
||||
```yml
|
||||
mybatis:
|
||||
#对应实体类路径
|
||||
type-aliases-package: com.example.mybatistest.entity
|
||||
#对应mapper映射文件路径
|
||||
mapper-locations: classpath:mapper/*.xml
|
||||
|
||||
#pagehelper物理分页配置
|
||||
pagehelper:
|
||||
helper-dialect: mysql
|
||||
reasonable: true
|
||||
support-methods-arguments: true
|
||||
params: count=countSql
|
||||
returnPageInfo: check
|
||||
|
||||
server:
|
||||
port: 8081
|
||||
|
||||
spring:
|
||||
datasource:
|
||||
name: mysqlTest
|
||||
type: com.alibaba.druid.pool.DruidDataSource
|
||||
#druid连接池相关配置
|
||||
druid:
|
||||
#监控拦截统计的filters
|
||||
filters: stat
|
||||
driver-class-name: com.mysql.jdbc.Driver
|
||||
url: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true
|
||||
username: root
|
||||
password: 123456
|
||||
#配置初始化大小,最小,最大
|
||||
initial-size: 1
|
||||
min-idle: 1
|
||||
max-active: 20
|
||||
#获取连接等待超时时间
|
||||
max-wait: 6000
|
||||
#间隔多久检测一次需要关闭的空闲连接
|
||||
time-between-eviction-runs-millis: 60000
|
||||
#一个连接在池中的最小生存时间
|
||||
min-evictable-idle-time-millis: 300000
|
||||
#打开PSCache,并指定每个连接上PSCache的大小。oracle设置为true,mysql设置为false。分库分表设置较多推荐设置
|
||||
pool-prepared-statements: false
|
||||
max-pool-prepared-statement-per-connection-size: 20
|
||||
http:
|
||||
encoding:
|
||||
charset: utf-8
|
||||
enabled: true
|
||||
```
|
||||
|
||||
## 2.编写代码
|
||||
|
||||
首先创建数据表,sql 语句如下:
|
||||
|
||||
```sql
|
||||
CREATE TABLE `user` (
|
||||
`id` int(11) NOT NULL AUTO_INCREMENT,
|
||||
`name` varchar(255) NOT NULL,
|
||||
`age` tinyint(4) NOT NULL DEFAULT '0',
|
||||
`password` varchar(255) NOT NULL DEFAULT '123456',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
|
||||
```
|
||||
|
||||
然后在 entity 包中创建实体类 User.java
|
||||
|
||||
```java
|
||||
public class User {
|
||||
private int id;
|
||||
private String name;
|
||||
private int age;
|
||||
private String password;
|
||||
|
||||
public User(int id, String name, int age, String password) {
|
||||
this.id = id;
|
||||
this.name = name;
|
||||
this.age = age;
|
||||
this.password = password;
|
||||
}
|
||||
public User(){}
|
||||
//getter setter自行添加
|
||||
}
|
||||
```
|
||||
|
||||
在 dao 包下创建 UserDao.java
|
||||
|
||||
```java
|
||||
public interface UserDao {
|
||||
//插入用户
|
||||
int insert(User user);
|
||||
//根据id查询
|
||||
User selectById(String id);
|
||||
//查询所有
|
||||
List<User> selectAll();
|
||||
}
|
||||
```
|
||||
|
||||
在 mapper 文件夹下创建 UserMapper.xml,具体的 xml 编写方法查看文首的官方文档。
|
||||
|
||||
```xml
|
||||
<?xml version="1.0" encoding="utf-8" ?>
|
||||
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
|
||||
<mapper namespace="com.example.mybatistest.dao.UserDao">
|
||||
<sql id="BASE_TABLE">
|
||||
user
|
||||
</sql>
|
||||
<sql id="BASE_COLUMN">
|
||||
id,name,age,password
|
||||
</sql>
|
||||
|
||||
<insert id="insert" parameterType="com.example.mybatistest.entity.User" useGeneratedKeys="true" keyProperty="id">
|
||||
INSERT INTO <include refid="BASE_TABLE"/>
|
||||
<trim prefix="(" suffix=")" suffixOverrides=",">
|
||||
name,password,
|
||||
<if test="age!=null">
|
||||
age
|
||||
</if>
|
||||
</trim>
|
||||
<trim prefix=" VALUE(" suffix=")" suffixOverrides=",">
|
||||
#{name,jdbcType=VARCHAR},#{password},
|
||||
<if test="age!=null">
|
||||
#{age}
|
||||
</if>
|
||||
</trim>
|
||||
</insert>
|
||||
|
||||
<select id="selectById" resultType="com.example.mybatistest.entity.User">
|
||||
select
|
||||
<include refid="BASE_COLUMN"/>
|
||||
from
|
||||
<include refid="BASE_TABLE"/>
|
||||
where id=#{id}
|
||||
</select>
|
||||
|
||||
<select id="selectAll" resultType="com.example.mybatistest.entity.User">
|
||||
select
|
||||
<include refid="BASE_COLUMN"/>
|
||||
from
|
||||
<include refid="BASE_TABLE"/>
|
||||
</select>
|
||||
</mapper>
|
||||
```
|
||||
|
||||
至此使用 mybatis 的代码编写完了,之后要用时调用 dao 接口中的方法即可。
|
||||
|
||||
## 3.测试
|
||||
|
||||
我们通过编写 service,controller 然后使用 postman 进行测试。
|
||||
|
||||
首先编写 UserService.java,代码如下:
|
||||
|
||||
```java
|
||||
@Component
|
||||
public class UserService {
|
||||
|
||||
@Autowired
|
||||
private UserDao userDao;
|
||||
|
||||
public User getByUserId(String id){
|
||||
return userDao.selectById(id);
|
||||
}
|
||||
//获取全部用户
|
||||
public List<User> getAll(){
|
||||
return userDao.selectAll();
|
||||
}
|
||||
//测试分页
|
||||
public PageInfo<User> getAll(int pageNum,int pageSize){
|
||||
PageHelper.startPage(pageNum,pageSize);
|
||||
List<User> users = userDao.selectAll();
|
||||
System.out.println(users.size());
|
||||
PageInfo<User> result = new PageInfo<>(users);
|
||||
return result;
|
||||
}
|
||||
|
||||
public int insert(User user){
|
||||
return userDao.insert(user);
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
编写 UserController.java
|
||||
|
||||
```java
|
||||
@RestController
|
||||
public class UserController {
|
||||
|
||||
@Autowired
|
||||
private UserService userService;
|
||||
|
||||
@GetMapping("/user/{userId}")
|
||||
public User getUser(@PathVariable String userId){
|
||||
return userService.getByUserId(userId);
|
||||
}
|
||||
|
||||
@GetMapping("/user")
|
||||
public List<User> getAll(){
|
||||
return userService.getAll();
|
||||
}
|
||||
|
||||
@GetMapping("/user/page/{pageNum}")
|
||||
public Object getPage(@PathVariable int pageNum,
|
||||
@RequestParam(name = "pageSize",required = false,defaultValue = "10") int pageSize){
|
||||
return userService.getAll(pageNum,pageSize);
|
||||
}
|
||||
|
||||
@PostMapping("/user")
|
||||
public Object addOne(User user){
|
||||
userService.insert(user);
|
||||
return user;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
启动项目,通过 postman 进行请求测试,测试结果如下:
|
||||
|
||||
- 插入数据:
|
||||
|
||||
|
||||
|
||||
- 查询数据
|
||||
|
||||
|
||||
|
||||
- 分页查询
|
||||
|
||||

|
||||
|
||||
## 4.注解编写 sql
|
||||
|
||||
上面使用的是 xml 方式编写 sql 代码,其实 mybatis 也支持在注解中编写 sql,这样可以避免编写复杂的 xml 查询文件,但同时也将 sql 语句耦合到了代码中,也不易实现复杂查询,因此多用于简单 sql 语句的编写。
|
||||
|
||||
要使用注解首先将 applicaton.yml 配置文件中的`mapper-locations: classpath:mapper/*.xml`注释掉。然后在 UserDao.java 中加入 sql 注解,代码如下:
|
||||
|
||||
```java
|
||||
public interface UserDao {
|
||||
//插入用户
|
||||
@Insert("insert into user(name,age,password) value(#{name},#{age},#{password})")
|
||||
@Options(useGeneratedKeys=true,keyColumn="id",keyProperty="id")
|
||||
int insert(User user);
|
||||
//根据id查询
|
||||
@Select("select * from user where id=#{id}")
|
||||
User selectById(String id);
|
||||
//查询所有
|
||||
@Select("select * from user")
|
||||
List<User> selectAll();
|
||||
}
|
||||
```
|
||||
|
||||
然后重新启动项目测试,测试结果跟上面完全一样。
|
||||
@ -1,143 +0,0 @@
|
||||
---
|
||||
id: "2018-09-05-10-38"
|
||||
date: "2018/09/05 10:38:00"
|
||||
title: "springboot整合ActiveMQ(1)"
|
||||
tags: ["java", "spring","springboot","消息队列","activeMQ"]
|
||||
categories:
|
||||
- "java"
|
||||
- "spring boot学习"
|
||||
---
|
||||
|
||||
**说明:acitveMQ 版本为:5.9.1,springboot 版本为 2.0.3,项目地址:[点击跳转](https://github.com/FleyX/demo-project/tree/master/jms_demo)**<br/>
|
||||
|
||||
## 一. 下载安装(windows)
|
||||
|
||||
  官方下载地址:[点我跳转](http://activemq.apache.org/download-archives.html),选择 windows 安装包下载,然后解压,解压后运行 bin 目录下的**activemq.bat**启动服务,无报错即可启动成功。默认管理地址为:[localhost:8161/admin](localhost:8161/admin),默认管理员账号密码为**admin**/**admin**。
|
||||
|
||||
## 二. springboot 整合
|
||||
|
||||
### 1. 创建 springboot 项目
|
||||
|
||||
  创建 springboot web 项目,加入 spring-boot-starter-activemq 依赖。
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-activemq</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
  然后编辑配合文件,加上一个配置:61616 为 activeMQ 的默认端口,暂时不做其他配置,使用默认值。
|
||||
|
||||
```yml
|
||||
spring:
|
||||
activemq:
|
||||
broker-url: tcp://localhost:61616
|
||||
```
|
||||
|
||||
### 2. 创建生产者消费者
|
||||
|
||||
  springboot 中 activeMQ 的默认配置为**生产-消费者模式**,还有一种模式为**发布-订阅模式**后面再讲。项目目录如下:
|
||||
|
||||

|
||||
|
||||
  首先编写配置类 Config.java,代码如下
|
||||
|
||||
```java
|
||||
@Configuration
|
||||
public class Config {
|
||||
@Bean(name = "queue2")
|
||||
public Queue queue2(){
|
||||
return new ActiveMQQueue("active.queue2");
|
||||
}
|
||||
|
||||
@Bean(name = "queue1")
|
||||
public Queue queue1(){
|
||||
return new ActiveMQQueue("active.queue1");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
上面的代码建立了两个消息队列 queue1,queue2,分别由 queue1 和 queue2 这两个 Bean 注入到 Spring 容器中。程序运行后会在 activeMQ 的管理页面->queue 中看到如下:
|
||||
|
||||

|
||||
|
||||
<!-- more -->
|
||||
|
||||
  生产者 Producer.java 代码如下:
|
||||
|
||||
```java
|
||||
@RestController
|
||||
public class Producer {
|
||||
@Autowired
|
||||
private JmsMessagingTemplate jmsMessagingTemplate;
|
||||
@Autowired()
|
||||
@Qualifier("queue2")
|
||||
private Queue queue2;
|
||||
@Autowired()
|
||||
@Qualifier("queue1")
|
||||
private Queue queue1;
|
||||
|
||||
@GetMapping("/queue2")
|
||||
public void sendMessage1(String message){
|
||||
jmsMessagingTemplate.convertAndSend(queue2,"I'm from queue2:"+message);
|
||||
}
|
||||
|
||||
@GetMapping("/queue1")
|
||||
public void sendMessage2(String message){
|
||||
jmsMessagingTemplate.convertAndSend(queue1,"I'm from queue1:"+message);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
上面的类创建了两个 GET 接口,访问这两个接口分别向 queue1 和 queue2 中发送消息。
|
||||
|
||||
消费者 Comsumer.java 代码如下:
|
||||
|
||||
```java
|
||||
@Component //将该类注解到Spring 容器中
|
||||
public class Comsumer {
|
||||
//接受消息队列1消息
|
||||
@JmsListener(destination = "active.queue1") //监听active.queue1消息队列
|
||||
public void readActiveQueue11(String message){
|
||||
System.out.println(1+message);
|
||||
}
|
||||
|
||||
//接受消息队列1消息
|
||||
@JmsListener(destination = "active.queue1")
|
||||
public void readActiveQueue12(String message){
|
||||
System.out.println(2+message);
|
||||
}
|
||||
|
||||
//接受消息队列2消息
|
||||
@JmsListener(destination = "active.queue2")
|
||||
public void readActiveQueue21(String message){
|
||||
System.out.println(1+message);
|
||||
}
|
||||
|
||||
//接受消息队列2消息
|
||||
@JmsListener(destination = "active.queue2")
|
||||
public void readActiveQueue22(String message){
|
||||
System.out.println(2+message);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
上面的代码定义了 4 个消费者,每两个消费一个消息队列。
|
||||
|
||||
### 3. 运行
|
||||
|
||||
  启动项目后分别向/queue1?message=niihao,/queue2?message=nihaoa 发送 http 请求,然后我们可以在控制台中看到如下输出:
|
||||
|
||||
```
|
||||
2I'm from queue2:nihaoa
|
||||
1I'm from queue2:nihaoa
|
||||
2I'm from queue1:nihao
|
||||
1I'm from queue1:nihao
|
||||
```
|
||||
|
||||
消息都成功被消费者消费,从打印结果也可看出生产者消费者的一个特点:一个消息只会被一个消费者消费。同时在管理页面中可以看到:
|
||||
|
||||
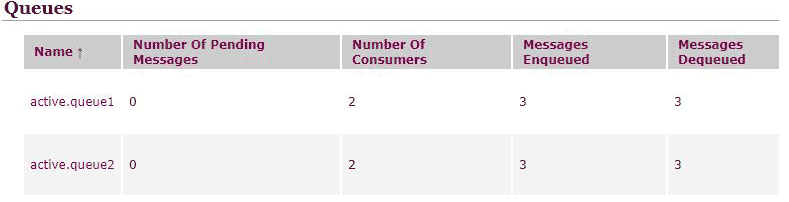
|
||||
|
||||
每个消息队列有两个消费者,队列进入了三个消息,出了三个消息,说明消息都被消费掉了,如果注释掉消费者代码,再次运行,然后发送消息就会发现 MessagesEnqueued 数量大于 MessagesDequeued,然后再让消费者上线会立即消费掉队列中的消息。
|
||||
@ -1,163 +0,0 @@
|
||||
---
|
||||
id: "2018-09-06-10-38"
|
||||
date: "2018/09/06 10:38:00"
|
||||
title: "springboot整合ActiveMQ(2)"
|
||||
tags: ["java", "spring","springboot","消息队列","activeMQ"]
|
||||
categories:
|
||||
- "java"
|
||||
- "spring boot学习"
|
||||
---
|
||||
|
||||
  单个 MQ 节点总是不可靠的,一旦该节点出现故障,MQ 服务就不可用了,势必会产生较大的损失。这里记录 activeMQ 如何开启主从备份,一旦 master(主节点故障),slave(从节点)立即提供服务,实现原理是运行多个 MQ 使用同一个持久化数据源,这里以 jdbc 数据源为例。同一时间只有一个节点(节点 A)能够抢到数据库的表锁,其他节点进入阻塞状态,一旦 A 发生错误崩溃,其他节点就会重新获取表锁,获取到锁的节点成为 master,其他节点为 slave,如果节点 A 重新启动,也将成为 slave。
|
||||
|
||||
  主从备份解决了单节点故障的问题,但是同一时间提供服务的只有一个 master,显然是不能面对数据量的增长,所以需要一种横向拓展的集群方式来解决面临的问题。
|
||||
|
||||
### 一、activeMQ 设置
|
||||
|
||||
#### 1、平台版本说明:
|
||||
|
||||
- 平台:windows
|
||||
- activeMQ 版本:5.9.1,[下载地址](https://www.apache.org/dist/activemq/5.9.1/apache-activemq-5.9.1-bin.zip.asc)
|
||||
- jdk 版本:1.8
|
||||
|
||||
#### 2、下载 jdbc 依赖
|
||||
|
||||
  下载下面三个依赖包,放到 activeMQ 安装目录下的 lib 文件夹中。
|
||||
|
||||
[mysql 驱动](http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.38/mysql-connector-java-5.1.38.jar)
|
||||
|
||||
[dhcp 依赖](http://central.maven.org/maven2/org/apache/commons/commons-dbcp2/2.1.1/commons-dbcp2-2.1.1.jar)
|
||||
|
||||
[commons-pool2 依赖](http://maven.aliyun.com/nexus/service/local/artifact/maven/redirect?r=jcenter&g=org.apache.commons&a=commons-pool2&v=2.6.0&e=jar)
|
||||
|
||||
###二、主从备份
|
||||
|
||||
####1、修改 jettty
|
||||
|
||||
  首先修改 conf->jetty.xml,这里是修改 activemq 的 web 管理端口,管理界面账号密码默认为 admin/admin
|
||||
|
||||
```xml
|
||||
<bean id="jettyPort" class="org.apache.activemq.web.WebConsolePort" init-method="start">
|
||||
<!-- the default port number for the web console -->
|
||||
<property name="port" value="8161"/>
|
||||
</bean>
|
||||
```
|
||||
|
||||
<!-- more -->
|
||||
|
||||
####2、修改 activemq.xml
|
||||
|
||||
  然后修改 conf->activemq.xml
|
||||
|
||||
- 设置连接方式
|
||||
|
||||
默认是下面五种连接方式都打开,这里我们只要 tcp,把其他的都注释掉,然后在这里设置 activemq 的服务端口,可以看到每种连接方式都对应一个端口。
|
||||
|
||||
```xml
|
||||
<transportConnectors>
|
||||
<!-- DOS protection, limit concurrent connections to 1000 and frame size to 100MB -->
|
||||
<transportConnector name="openwire" uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
|
||||
<!-- <transportConnector name="amqp" uri="amqp://0.0.0.0:5672?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
|
||||
<transportConnector name="stomp" uri="stomp://0.0.0.0:61613?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
|
||||
<transportConnector name="mqtt" uri="mqtt://0.0.0.0:1883?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
|
||||
<transportConnector name="ws" uri="ws://0.0.0.0:61614?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/> -->
|
||||
</transportConnectors>
|
||||
```
|
||||
|
||||
* 设置 jdbc 数据库
|
||||
|
||||
mysql 数据库中创建 activemq 库,在`broker`标签的下面也就是根标签`beans`的下一级创建一个 bean 节点,内容如下:
|
||||
|
||||
```xml
|
||||
<bean id="mysql-qs" class="org.apache.commons.dbcp2.BasicDataSource" destroy-method="close">
|
||||
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
|
||||
<property name="url" value="jdbc:mysql://localhost:3306/activemq?relaxAutoCommit=true"/>
|
||||
<property name="username" value="root"/>
|
||||
<property name="password" value="123456"/>
|
||||
<property name="poolPreparedStatements" value="true"/>
|
||||
</bean>
|
||||
```
|
||||
|
||||
* 设置数据源
|
||||
|
||||
首先修改 broker 节点,设置 name 和 persistent(默认为 true),也可不做修改,修改后如下:
|
||||
|
||||
```xml
|
||||
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="mq1" persistent="true" dataDirectory="${activemq.data}">
|
||||
```
|
||||
|
||||
然后设置持久化方式,使用到我们之前设置的 mysql-qs
|
||||
|
||||
```xml
|
||||
<persistenceAdapter>
|
||||
<!-- <kahaDB directory="${activemq.data}/kahadb"/> -->
|
||||
<jdbcPersistenceAdapter dataDirectory="${activemq.base}/activemq-data" dataSource="#mysql-qs"/>
|
||||
</persistenceAdapter>
|
||||
```
|
||||
|
||||
#### 3、启动
|
||||
|
||||
  设置完毕后启动 activemq(双击 bin 中的 acitveMQ.jar),启动完成后可以看到如下日志信息:
|
||||
|
||||
```verilog
|
||||
INFO | Using a separate dataSource for locking: org.apache.commons.dbcp2.BasicDataSource@179ece50
|
||||
INFO | Attempting to acquire the exclusive lock to become the Master broker
|
||||
INFO | Becoming the master on dataSource: org.apache.commons.dbcp2.BasicDataSource@179ece50
|
||||
```
|
||||
|
||||
接着我们修改一下 tcp 服务端口,改为 61617,然后重新启动,日志信息如下:
|
||||
|
||||
```verilog
|
||||
INFO | Using a separate dataSource for locking: org.apache.commons.dbcp2.BasicDataSource@179ece50
|
||||
INFO | Attempting to acquire the exclusive lock to become the Master broker
|
||||
INFO | Failed to acquire lock. Sleeping for 10000 milli(s) before trying again...
|
||||
INFO | Failed to acquire lock. Sleeping for 10000 milli(s) before trying again...
|
||||
INFO | Failed to acquire lock. Sleeping for 10000 milli(s) before trying again...
|
||||
INFO | Failed to acquire lock. Sleeping for 10000 milli(s) before trying again...
|
||||
```
|
||||
|
||||
可以看到从节点一直在尝试获取表锁成为主节点,这样一旦主节点失效,从节点能够立刻取代主节点提供服务。这样我们便实现了主从备份。
|
||||
|
||||
### 三、负载均衡
|
||||
|
||||
  activemq 可以实现多个 mq 之间进行路由,假设有两个 mq,分别为 brokerA 和 brokerB,当一条消息发送到 brokerA 的队列 test 中,有一个消费者连上了 brokerB,并且想要获取 test 队列,brokerA 中的 test 队列就会路由到 brokerB 上。
|
||||
|
||||
   开启负载均衡需要设置`networkConnectors`节点,静态路由配置如下:
|
||||
|
||||
```xml
|
||||
<networkConnectors>
|
||||
<networkConnector uri="static:failover://(tcp://localhost:61616,tcp://localhost:61617)" duplex="false"/>
|
||||
</networkConnectors>
|
||||
```
|
||||
|
||||
brokerA 和 brokerB 都要设置该配置,以连上对方。
|
||||
|
||||
### 四、测试
|
||||
|
||||
####1、建立 mq
|
||||
|
||||
  组建两组 broker,每组做主从配置。
|
||||
|
||||
- brokerA:
|
||||
- 主:设置 web 管理端口 8761,设置 mq 名称`mq`,设置数据库地址为 activemq,设置 tcp 服务端口 61616,设置负载均衡静态路由`static:failover://(tcp://localhost:61618,tcp://localhost:61619)`,然后启动
|
||||
- 从:上面的基础上修改 tcp 服务端口为 61617,然后启动
|
||||
- brokerB:
|
||||
- 主:设置 web 管理端口 8762,设置 mq 名称`mq1`,设置数据库地址 activemq1,设置 tcp 服务端口 61618,设置负载均衡静态路由`static:failover://(tcp://localhost:61616,tcp://localhost:61617)`,然后启动
|
||||
- 从:上面的基础上修改 tcp 服务端口为 61619,然后启动
|
||||
|
||||
#### 2、springboot 测试
|
||||
|
||||
   沿用上一篇的项目,修改配置文件的 broker-url 为`failover:(tcp://localhost:61616,tcp://localhost:61617,tcp://localhost:61618,tcp://localhost:61619)`,然后启动项目访问会在控制台看到如下日志:
|
||||
|
||||
```java
|
||||
2018-07-31 15:09:25.076 INFO 12780 --- [ActiveMQ Task-1] o.a.a.t.failover.FailoverTransport : Successfully connected to tcp://localhost:61618
|
||||
1I'm from queue1:hello
|
||||
2018-07-31 15:09:26.599 INFO 12780 --- [ActiveMQ Task-1] o.a.a.t.failover.FailoverTransport : Successfully connected to tcp://localhost:61618
|
||||
2I'm from queue1:hello
|
||||
2018-07-31 15:09:29.002 INFO 12780 --- [ActiveMQ Task-1] o.a.a.t.failover.FailoverTransport : Successfully connected to tcp://localhost:61616
|
||||
1I'm from queue1:hello
|
||||
2018-07-31 15:09:34.931 INFO 12780 --- [ActiveMQ Task-1] o.a.a.t.failover.FailoverTransport : Successfully connected to tcp://localhost:61618
|
||||
2I'm from queue1:hello
|
||||
```
|
||||
|
||||
证明负载均衡成功。
|
||||
@ -1,323 +0,0 @@
|
||||
---
|
||||
id: "2018-09-10-10-38"
|
||||
date: "2018/09/10 10:38:00"
|
||||
title: "springboot配置读写分离(Mybatis)"
|
||||
tags: ["java", "spring","springboot","mysql","主从备份","读写分离"]
|
||||
categories:
|
||||
- "java"
|
||||
- "spring boot学习"
|
||||
---
|
||||
|
||||
  近日工作任务较轻,有空学习学习技术,遂来研究如果实现读写分离。这里用博客记录下过程,一方面可备日后查看,同时也能分享给大家(网上的资料真的大都是抄来抄去,,还不带格式的,看的真心难受)。
|
||||
|
||||
[完整代码](https://github.com/FleyX/demo-project/tree/master/dxfl)
|
||||
|
||||
## 1、背景
|
||||
|
||||
  一个项目中数据库最基础同时也是最主流的是单机数据库,读写都在一个库中。当用户逐渐增多,单机数据库无法满足性能要求时,就会进行读写分离改造(适用于读多写少),写操作一个库,读操作多个库,通常会做一个数据库集群,开启主从备份,一主多从,以提高读取性能。当用户更多读写分离也无法满足时,就需要分布式数据库了(可能以后会学习怎么弄)。
|
||||
|
||||
  正常情况下读写分离的实现,首先要做一个一主多从的数据库集群,同时还需要进行数据同步。这一篇记录如何用 mysql 搭建一个一主多次的配置,下一篇记录代码层面如何实现读写分离。
|
||||
|
||||
## 2、搭建一主多从数据库集群
|
||||
|
||||
  主从备份需要多台虚拟机,我是用 wmware 完整克隆多个实例,注意直接克隆的虚拟机会导致每个数据库的 uuid 相同,需要修改为不同的 uuid。修改方法参考这个:[点击跳转](https://blog.csdn.net/pratise/article/details/80413198)。
|
||||
|
||||
- 主库配置
|
||||
|
||||
主数据库(master)中新建一个用户用于从数据库(slave)读取主数据库二进制日志,sql 语句如下:
|
||||
|
||||
```sql
|
||||
mysql> CREATE USER 'repl'@'%' IDENTIFIED BY '123456';#创建用户
|
||||
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';#分配权限
|
||||
mysql>flush privileges; #刷新权限
|
||||
```
|
||||
|
||||
同时修改 mysql 配置文件开启二进制日志,新增部分如下:
|
||||
|
||||
```sql
|
||||
[mysqld]
|
||||
server-id=1
|
||||
log-bin=master-bin
|
||||
log-bin-index=master-bin.index
|
||||
```
|
||||
|
||||
然后重启数据库,使用`show master status;`语句查看主库状态,如下所示:
|
||||
|
||||

|
||||
|
||||
<!-- more -->
|
||||
|
||||
- 从库配置
|
||||
|
||||
同样先新增几行配置:
|
||||
|
||||
```sql
|
||||
[mysqld]
|
||||
server-id=2
|
||||
relay-log-index=slave-relay-bin.index
|
||||
relay-log=slave-relay-bin
|
||||
```
|
||||
|
||||
然后重启数据库,使用如下语句连接主库:
|
||||
|
||||
```sql
|
||||
CHANGE MASTER TO
|
||||
MASTER_HOST='192.168.226.5',
|
||||
MASTER_USER='root',
|
||||
MASTER_PASSWORD='123456',
|
||||
MASTER_LOG_FILE='master-bin.000003',
|
||||
MASTER_LOG_POS=154;
|
||||
```
|
||||
|
||||
接着运行`start slave;`开启备份,正常情况如下图所示:Slave_IO_Running 和 Slave_SQL_Running 都为 yes。
|
||||
|
||||
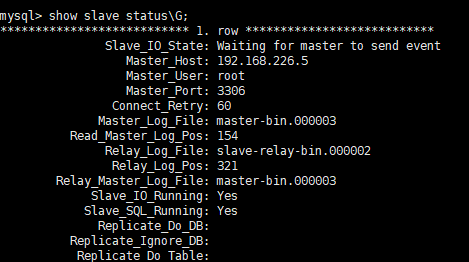
|
||||
|
||||
可以用这个步骤开启多个从库。
|
||||
|
||||
  默认情况下备份是主库的全部操作都会备份到从库,实际可能需要忽略某些库,可以在主库中增加如下配置:
|
||||
|
||||
```sql
|
||||
# 不同步哪些数据库
|
||||
binlog-ignore-db = mysql
|
||||
binlog-ignore-db = test
|
||||
binlog-ignore-db = information_schema
|
||||
|
||||
# 只同步哪些数据库,除此之外,其他不同步
|
||||
binlog-do-db = game
|
||||
```
|
||||
|
||||
## 3、代码层面进行读写分离
|
||||
|
||||
  代码环境是 springboot+mybatis+druib 连接池。想要读写分离就需要配置多个数据源,在进行写操作是选择写的数据源,读操作时选择读的数据源。其中有两个关键点:
|
||||
|
||||
- 如何切换数据源
|
||||
- 如何根据不同的方法选择正确的数据源
|
||||
|
||||
### 1)、如何切换数据源
|
||||
|
||||
  通常用 springboot 时都是使用它的默认配置,只需要在配置文件中定义好连接属性就行了,但是现在我们需要自己来配置了,spring 是支持多数据源的,多个 datasource 放在一个 HashMap`TargetDataSource`中,通过`dertermineCurrentLookupKey`获取 key 来觉定要使用哪个数据源。因此我们的目标就很明确了,建立多个 datasource 放到 TargetDataSource 中,同时重写 dertermineCurrentLookupKey 方法来决定使用哪个 key。
|
||||
|
||||
### 2)、如何选择数据源
|
||||
|
||||
  事务一般是注解在 Service 层的,因此在开始这个 service 方法调用时要确定数据源,有什么通用方法能够在开始执行一个方法前做操作呢?相信你已经想到了那就是**切面 **。怎么切有两种办法:
|
||||
|
||||
- 注解式,定义一个只读注解,被该数据标注的方法使用读库
|
||||
- 方法名,根据方法名写切点,比如 getXXX 用读库,setXXX 用写库
|
||||
|
||||
### 3)、代码编写
|
||||
|
||||
#### a、编写配置文件,配置两个数据源信息
|
||||
|
||||
  只有必填信息,其他都有默认设置
|
||||
|
||||
```yml
|
||||
mysql:
|
||||
datasource:
|
||||
#读库数目
|
||||
num: 1
|
||||
type-aliases-package: com.example.dxfl.dao
|
||||
mapper-locations: classpath:/mapper/*.xml
|
||||
config-location: classpath:/mybatis-config.xml
|
||||
write:
|
||||
url: jdbc:mysql://192.168.226.5:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true
|
||||
username: root
|
||||
password: 123456
|
||||
driver-class-name: com.mysql.jdbc.Driver
|
||||
read:
|
||||
url: jdbc:mysql://192.168.226.6:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true
|
||||
username: root
|
||||
password: 123456
|
||||
driver-class-name: com.mysql.jdbc.Driver
|
||||
```
|
||||
|
||||
#### b、编写 DbContextHolder 类
|
||||
|
||||
  这个类用来设置数据库类别,其中有一个 ThreadLocal 用来保存每个线程的是使用读库,还是写库。代码如下:
|
||||
|
||||
```java
|
||||
/**
|
||||
* Description 这里切换读/写模式
|
||||
* 原理是利用ThreadLocal保存当前线程是否处于读模式(通过开始READ_ONLY注解在开始操作前设置模式为读模式,
|
||||
* 操作结束后清除该数据,避免内存泄漏,同时也为了后续在该线程进行写操作时任然为读模式
|
||||
* @author fxb
|
||||
* @date 2018-08-31
|
||||
*/
|
||||
public class DbContextHolder {
|
||||
|
||||
private static Logger log = LoggerFactory.getLogger(DbContextHolder.class);
|
||||
public static final String WRITE = "write";
|
||||
public static final String READ = "read";
|
||||
|
||||
private static ThreadLocal<String> contextHolder= new ThreadLocal<>();
|
||||
|
||||
public static void setDbType(String dbType) {
|
||||
if (dbType == null) {
|
||||
log.error("dbType为空");
|
||||
throw new NullPointerException();
|
||||
}
|
||||
log.info("设置dbType为:{}",dbType);
|
||||
contextHolder.set(dbType);
|
||||
}
|
||||
|
||||
public static String getDbType() {
|
||||
return contextHolder.get() == null ? WRITE : contextHolder.get();
|
||||
}
|
||||
|
||||
public static void clearDbType() {
|
||||
contextHolder.remove();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### c、重写 determineCurrentLookupKey 方法
|
||||
|
||||
  spring 在开始进行数据库操作时会通过这个方法来决定使用哪个数据库,因此我们在这里调用上面 DbContextHolder 类的`getDbType()`方法获取当前操作类别,同时可进行读库的负载均衡,代码如下:
|
||||
|
||||
```java
|
||||
public class MyAbstractRoutingDataSource extends AbstractRoutingDataSource {
|
||||
|
||||
@Value("${mysql.datasource.num}")
|
||||
private int num;
|
||||
|
||||
private final Logger log = LoggerFactory.getLogger(this.getClass());
|
||||
|
||||
@Override
|
||||
protected Object determineCurrentLookupKey() {
|
||||
String typeKey = DbContextHolder.getDbType();
|
||||
if (typeKey == DbContextHolder.WRITE) {
|
||||
log.info("使用了写库");
|
||||
return typeKey;
|
||||
}
|
||||
//使用随机数决定使用哪个读库
|
||||
int sum = NumberUtil.getRandom(1, num);
|
||||
log.info("使用了读库{}", sum);
|
||||
return DbContextHolder.READ + sum;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### d、编写配置类
|
||||
|
||||
  由于要进行读写分离,不能再用 springboot 的默认配置,我们需要手动来进行配置。首先生成数据源,使用@ConfigurProperties 自动生成数据源:
|
||||
|
||||
```java
|
||||
/**
|
||||
* 写数据源
|
||||
*
|
||||
* @Primary 标志这个 Bean 如果在多个同类 Bean 候选时,该 Bean 优先被考虑。
|
||||
* 多数据源配置的时候注意,必须要有一个主数据源,用 @Primary 标志该 Bean
|
||||
*/
|
||||
@Primary
|
||||
@Bean
|
||||
@ConfigurationProperties(prefix = "mysql.datasource.write")
|
||||
public DataSource writeDataSource() {
|
||||
return new DruidDataSource();
|
||||
}
|
||||
```
|
||||
|
||||
读数据源类似,注意有多少个读库就要设置多少个读数据源,Bean 名为 read+序号。
|
||||
|
||||
  然后设置数据源,使用的是我们之前写的 MyAbstractRoutingDataSource 类
|
||||
|
||||
```java
|
||||
/**
|
||||
* 设置数据源路由,通过该类中的determineCurrentLookupKey决定使用哪个数据源
|
||||
*/
|
||||
@Bean
|
||||
public AbstractRoutingDataSource routingDataSource() {
|
||||
MyAbstractRoutingDataSource proxy = new MyAbstractRoutingDataSource();
|
||||
Map<Object, Object> targetDataSources = new HashMap<>(2);
|
||||
targetDataSources.put(DbContextHolder.WRITE, writeDataSource());
|
||||
targetDataSources.put(DbContextHolder.READ+"1", read1());
|
||||
proxy.setDefaultTargetDataSource(writeDataSource());
|
||||
proxy.setTargetDataSources(targetDataSources);
|
||||
return proxy;
|
||||
}
|
||||
```
|
||||
|
||||
  接着需要设置 sqlSessionFactory
|
||||
|
||||
```java
|
||||
/**
|
||||
* 多数据源需要自己设置sqlSessionFactory
|
||||
*/
|
||||
@Bean
|
||||
public SqlSessionFactory sqlSessionFactory() throws Exception {
|
||||
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
|
||||
bean.setDataSource(routingDataSource());
|
||||
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
|
||||
// 实体类对应的位置
|
||||
bean.setTypeAliasesPackage(typeAliasesPackage);
|
||||
// mybatis的XML的配置
|
||||
bean.setMapperLocations(resolver.getResources(mapperLocation));
|
||||
bean.setConfigLocation(resolver.getResource(configLocation));
|
||||
return bean.getObject();
|
||||
}
|
||||
```
|
||||
|
||||
  最后还得配置下事务,否则事务不生效
|
||||
|
||||
```java
|
||||
/**
|
||||
* 设置事务,事务需要知道当前使用的是哪个数据源才能进行事务处理
|
||||
*/
|
||||
@Bean
|
||||
public DataSourceTransactionManager dataSourceTransactionManager() {
|
||||
return new DataSourceTransactionManager(routingDataSource());
|
||||
}
|
||||
```
|
||||
|
||||
### 4)、选择数据源
|
||||
|
||||
  多数据源配置好了,但是代码层面如何选择选择数据源呢?这里介绍两种办法:
|
||||
|
||||
#### a、注解式
|
||||
|
||||
  首先定义一个只读注解,被这个注解方法使用读库,其他使用写库,如果项目是中途改造成读写分离可使用这个方法,无需修改业务代码,只要在只读的 service 方法上加一个注解即可。
|
||||
|
||||
```java
|
||||
@Target({ElementType.METHOD,ElementType.TYPE})
|
||||
@Retention(RetentionPolicy.RUNTIME)
|
||||
public @interface ReadOnly {
|
||||
}
|
||||
```
|
||||
|
||||
  然后写一个切面来切换数据使用哪种数据源,重写 getOrder 保证本切面优先级高于事务切面优先级,在启动类加上`@EnableTransactionManagement(order = 10)`,为了代码如下:
|
||||
|
||||
```java
|
||||
@Aspect
|
||||
@Component
|
||||
public class ReadOnlyInterceptor implements Ordered {
|
||||
private static final Logger log= LoggerFactory.getLogger(ReadOnlyInterceptor.class);
|
||||
|
||||
@Around("@annotation(readOnly)")
|
||||
public Object setRead(ProceedingJoinPoint joinPoint,ReadOnly readOnly) throws Throwable{
|
||||
try{
|
||||
DbContextHolder.setDbType(DbContextHolder.READ);
|
||||
return joinPoint.proceed();
|
||||
}finally {
|
||||
//清楚DbType一方面为了避免内存泄漏,更重要的是避免对后续在本线程上执行的操作产生影响
|
||||
DbContextHolder.clearDbType();
|
||||
log.info("清除threadLocal");
|
||||
}
|
||||
}
|
||||
|
||||
@Override
|
||||
public int getOrder() {
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### b、方法名式
|
||||
|
||||
  这种方法不许要注解,但是需要事务名称按一定规则编写,然后通过切面来设置数据库类别,比如`setXXX`设置为写、`getXXX`设置为读,代码我就不写了,应该都知道怎么写。
|
||||
|
||||
## 4、测试
|
||||
|
||||
  编写好代码来试试结果如何,下面是运行截图:
|
||||
|
||||

|
||||
|
||||
  断断续续写了好几天终于是写完了,,,如果有帮助到你,,欢迎 star 哦,,这里是完整代码地址:[点击跳转](https://github.com/FleyX/demo-project/tree/master/dxfl)
|
||||
@ -1,32 +0,0 @@
|
||||
---
|
||||
id: '2019-02-28-11-33'
|
||||
date: '2019/02/28 11:33'
|
||||
title: 'springCloud学习总览'
|
||||
tags: ['spring-boot', 'spring-cloud', 'spring微服务实战']
|
||||
categories:
|
||||
- 'java'
|
||||
- 'springCloud实战'
|
||||
---
|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](http://tapme.top/blog/detail/2019-02-28-11-33)
|
||||
|
||||
  写完最后一篇特意去看了看第一篇是什么时候写的———2018/11/19,到现在三个月多一点,总的来说这三个月通过《Spring 微服务实战》这本书,算是对微服务进行了一次扫盲学习。
|
||||
|
||||

|
||||
|
||||
  共计产生了如下 6 篇学习笔记:
|
||||
|
||||
- [springCloud 学习 1(集中式配置管理)](http://tapme.top/blog/detail/2018-11-19-15-57-00/)
|
||||
- [springCloud 学习 2(服务发现)](http://tapme.top/blog/detail/2018-11-22-15-57/)
|
||||
- [springCloud 学习 3(Netflix Hystrix 弹性客户端)](http://tapme.top/blog/detail/2018-11-28-15-57-00)
|
||||
- [springCloud 学习 4(Zuul 服务路由)](http://tapme.top/blog/detail/2019-01-03-19-19)
|
||||
- [springCloud 学习 5(Spring-Cloud-Stream 事件驱动)](http://tapme.top/blog/detail/2019-01-03-19-19)
|
||||
- [springCloud 学习 6(Spring Cloud Sleuth 分布式跟踪)](http://tapme.top/blog/detail/2019-01-03-19-19)
|
||||
|
||||
  总的来说这本书还是不错滴,虽然有些许错误(不确定是印刷错误还是排版),但是问题都不大。除了内容有点老:书中代码所有 spring boot 版本为`1.4.4`,spring cloud 版本为`Camden.SR5`。但是理念都是那些,新版本只有有更好的诠释方式,无需过分关注这个问题。
|
||||
|
||||
  spring cloud 的学习暂时告一段落。
|
||||
|
||||
_2019,Fighting!_
|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](http://tapme.top/blog/detail/2019-02-28-11-33)
|
||||
@ -1,290 +0,0 @@
|
||||
---
|
||||
id: "2018-11-19-15-57-00"
|
||||
date: "2018/11/19 15:57:00"
|
||||
title: "springCloud学习1(集中式配置管理)"
|
||||
tags: ["spring-boot", "spring-cloud-config","git"]
|
||||
categories:
|
||||
- "java"
|
||||
- "springCloud实战"
|
||||
---
|
||||
|
||||
  本篇项目代码存放于:[点击跳转](https://github.com/FleyX/demo-project/tree/master/springcloud/spring-cloud-config%E9%85%8D%E7%BD%AE%E4%B8%AD%E5%BF%83)
|
||||
|
||||
## 一、前言
|
||||
|
||||
  在开发普通的 web 应用中,我们通常是将配置项写在单独的配置文件中,比如`application.yml`,`application.properties`,但是在微服务架构中,可能会出现数百个微服务,如果每个微服务将配置文件写在自身的配置文件中,会导致配置文件的管理非常复杂。因此集中式的配置管理是非常有必要的,每个服务启动时从集中式的存储库中读取需要的配置信息。其模型如下:
|
||||
|
||||
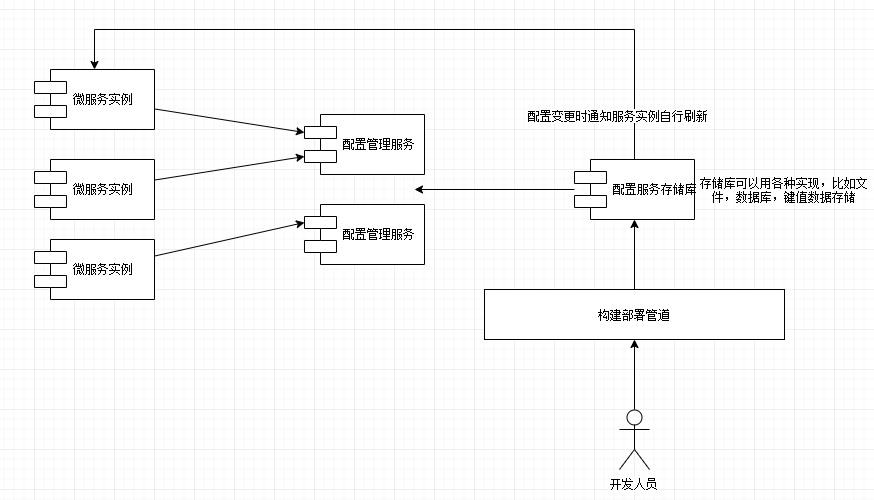
|
||||
|
||||
简单来说就是如下几点:
|
||||
|
||||
1. 启动一个微服务实例时向配置管理服务请求获取其所在环境的特定配置文件
|
||||
2. 实际的配置信息驻留在存储库中。可以选择不同的实现来保存配置数据,包含:源代码控制下的文件、关系数据库或键值数据存储
|
||||
3. 应用程序配置数据的实际管理和应用程序无关。配置的更改通常通过构建和部署管道来处理
|
||||
4. 进行配置管理更改时,必须通知使用该配置的服务实例
|
||||
|
||||
  由于本系列为 spring cloud,所以使用`Spring Cloud Config`来构建配置管理,当然还有很多其他优秀的解决方案(Etcd,Eureka,Consul...)。
|
||||
|
||||
## 二、构建配置服务
|
||||
|
||||
  spring cloud 是建立在 spring boot 的基础上的,因此需要有 spring boot 的构建基础。
|
||||
|
||||
### 1、pom 编写
|
||||
|
||||
  pom 主要依赖如下(篇幅原因列出主要内容,完整代码请到 github 上查看),spring boot 版本和 spring cloud 版本如下,之后不在赘述:
|
||||
|
||||
<!-- more -->
|
||||
|
||||
```xml
|
||||
<parent>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-parent</artifactId>
|
||||
<version>1.4.4.RELEASE</version>
|
||||
</parent>
|
||||
|
||||
<dependencyManagement>
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-dependencies</artifactId>
|
||||
<version>Camden.SR5</version>
|
||||
<type>pom</type>
|
||||
<scope>import</scope>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
</dependencyManagement>
|
||||
|
||||
<properties>
|
||||
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
|
||||
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
|
||||
<java.version>1.8</java.version>
|
||||
<spring-cloud.version>Camden.SR5</spring-cloud.version>
|
||||
</properties>
|
||||
|
||||
<dependencies>
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-config-server</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-starter-config</artifactId>
|
||||
</dependency>
|
||||
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-test</artifactId>
|
||||
<scope>test</scope>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
```
|
||||
|
||||
### 2、注解引导类
|
||||
|
||||
  只需在 spring boot 启动类上加入一个`@EnableConfigServer`注解即可。
|
||||
|
||||
### 3、配置服务配置编写(使用文件存储)
|
||||
|
||||
  这里是给**配置服务**使用的配置文件,用于声明端口,存储库类别等信息,并不是给其他微服务使用的配置。配置如下(使用文件存储配置信息):
|
||||
|
||||
```yaml
|
||||
server:
|
||||
port: 8888
|
||||
spring:
|
||||
profiles:
|
||||
# 使用文件系统来存储配置信息,需要设置为native
|
||||
active: native
|
||||
cloud:
|
||||
config:
|
||||
server:
|
||||
native:
|
||||
# 使用文件来存放配置文件,为每个应用程序提供用逗号分隔的文件夹列表
|
||||
searchLocations: file:///D:/configFolder/licensingservice
|
||||
```
|
||||
|
||||
### 4、创建供应用程序使用的配置文件
|
||||
|
||||
  通过上面的`searchLocations`可知目前有一个名为 licensingservice 的应用程序,在对应目录下创建如下三个配置文件:
|
||||
|
||||
- licensingservice.yml
|
||||
|
||||
```yaml
|
||||
server:
|
||||
port: 10010
|
||||
spring:
|
||||
application:
|
||||
name: licensingservice
|
||||
```
|
||||
|
||||
- licensingservice-dev.yml
|
||||
|
||||
```yaml
|
||||
server:
|
||||
port: 10011
|
||||
```
|
||||
|
||||
- licensingservice-prod.yml
|
||||
|
||||
```yaml
|
||||
server:
|
||||
port: 10012
|
||||
```
|
||||
|
||||
配置文件命名约定为:`应用程序名称-环境名称.yml`。现在启动应用便能通过 http 请求来获取配置了。
|
||||
|
||||
  请求[localhost:8888/licensingservice/default](localhost:8888/licensingservice/default),返回结果如下:
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "licensingservice",
|
||||
"profiles": ["default"],
|
||||
"label": null,
|
||||
"version": null,
|
||||
"state": null,
|
||||
"propertySources": [
|
||||
{
|
||||
"name": "file:///D:/configFolder/licensingservice/licensingservice.yml",
|
||||
"source": {
|
||||
"server.port": 10001,
|
||||
"spring.application.name": "licensingservice"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
  请求[localhost:8888/licensingservice/dev](localhost:8888/licensingservice/dev),返回结果如下:
|
||||
|
||||
```json
|
||||
{
|
||||
"name": "licensingservice",
|
||||
"profiles": ["dev"],
|
||||
"label": null,
|
||||
"version": null,
|
||||
"state": null,
|
||||
"propertySources": [
|
||||
{
|
||||
"name": "file:///D:/configFolder/licensingservice/licensingservice-dev.yml",
|
||||
"source": {
|
||||
"server.port": 10011
|
||||
}
|
||||
},
|
||||
{
|
||||
"name": "file:///D:/configFolder/licensingservice/licensingservice.yml",
|
||||
"source": {
|
||||
"server.port": 10001,
|
||||
"spring.application.name": "licensingservice"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## 二、和 spring boot 客户端集成
|
||||
|
||||
  上面写了如何使用 spring cloud config 构建配置服务,这一节来构建 licensingserivce 服务,使用上面的配置服务来获取配置文件。
|
||||
|
||||
### 1、创建 springboot 工程
|
||||
|
||||
  创建 springboot 项目 licensingservice,主要依赖如下:
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-web</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-config-client</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
### 2、编写配置文件
|
||||
|
||||
  共两个配置文件,`application.yml`,`bootstrap.yml`
|
||||
|
||||
- application.yml
|
||||
|
||||
本配置文件用于存放留在本地配置信息,如果存在同名配置,本地的会被覆盖,不会生效
|
||||
|
||||
```yaml
|
||||
server:
|
||||
port: 10099
|
||||
```
|
||||
|
||||
- bootstrap.yml
|
||||
|
||||
给 spring cloud config client 读取的配置文件,根据该配置向配置中心请求
|
||||
|
||||
```yaml
|
||||
spring:
|
||||
application:
|
||||
#指定名称,以便spring cloud config客户端知道查找哪个配置
|
||||
name: licensingservice
|
||||
profiles:
|
||||
#指定环境(default,dev,prod)
|
||||
active: dev
|
||||
cloud:
|
||||
config:
|
||||
#指定config server地址
|
||||
uri: http://localhost:8888
|
||||
```
|
||||
|
||||
PS:如果想要覆盖 bootstrap.yml 的配置可在启动命令加上-d 参数,如:
|
||||
|
||||
`java -Dsptring.cloud.config.uri=.... -Dspring.profiles.active=prod xxxxx.jar`
|
||||
|
||||
### 3、启动
|
||||
|
||||
  启动 licensingservice 可以发现启动端口为 10011,说明远程读取配置生效了。
|
||||
|
||||
## 三、使用 git 作为配置服务的数据源
|
||||
|
||||
### 1、创建源配置文件
|
||||
|
||||
  在 github 某个仓库下创建配置文件,比如在[https://github.com/FleyX/demo-project](https://github.com/FleyX/demo-project)仓库下的**springcloud/config**目录下创建 licengingservice 服务的配置文件。
|
||||
|
||||
### 2、修改 config server 配置文件
|
||||
|
||||
  修改 confsvr 中的 application.yml
|
||||
|
||||
```yaml
|
||||
server:
|
||||
port: 8888
|
||||
spring:
|
||||
profiles:
|
||||
# 使用文件系统来存储配置信息,需要设置为native,git设置为git
|
||||
active: git
|
||||
application:
|
||||
name: test
|
||||
cloud:
|
||||
config:
|
||||
server:
|
||||
native:
|
||||
# 使用文件来存放配置文件,为每个应用程序提供用逗号分隔的文件夹列表
|
||||
searchLocations: file:///D:/configFolder/licensingservice
|
||||
git:
|
||||
uri: https://github.com/FleyX/demo-project
|
||||
# 查找配置文件路径(,分隔)
|
||||
search-paths: springcloud/config/licensingservice
|
||||
#如果为公开仓库,用户名密码可不填写
|
||||
username:
|
||||
password:
|
||||
#配置git仓库的分支
|
||||
label: master
|
||||
```
|
||||
|
||||
### 3、启动
|
||||
|
||||
  重新启动,即可发现配置成功生效。
|
||||
|
||||
## 四、配置刷新
|
||||
|
||||
  使用 spring cloud 配置服务器时,有一个问题是如何在属性变化时动态刷新应用程序。spring cloud 配置服务始终提供最新版本的属性,对低层存储库属性的更改将会是最新的。但是 config client 并不会知道配置的变更,因此不会自动刷新属性。
|
||||
|
||||
  Spring Boot Actuator 提供了一个`@RefreshScope`属性来重新读取应用程序配置信息,开发人员可通过`/refresh`进行刷新。该注释需要注释在启动入口类上。注意:**只会加载自定义 Spring 属性,例如数据库,端口等配置不会重新加载**。
|
||||
|
||||
## 总结
|
||||
|
||||
  本篇只是用到了 spring-cloud-config 这个来进行配置集中管理,并没有涉及到微服务,在下一篇将开始微服务的学习。
|
||||
  本篇两个项目代码存放于:[点击跳转](https://github.com/FleyX/demo-project/tree/master/springcloud/spring-cloud-config%E9%85%8D%E7%BD%AE%E4%B8%AD%E5%BF%83)
|
||||
@ -1,453 +0,0 @@
|
||||
---
|
||||
id: "2018-11-22-15-57"
|
||||
date: "2018/11/22 15:57"
|
||||
title: "springCloud学习2(服务发现)"
|
||||
tags: ["spring-boot", "spring-cloud","eureka"]
|
||||
categories:
|
||||
- "java"
|
||||
- "springCloud实战"
|
||||
---
|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](http://tapme.top/blog/detail/2018-11-22-15-57)
|
||||
|
||||
本篇代码存放于:[github](https://github.com/FleyX/demo-project/tree/master/springcloud/spring-cloud%E6%9C%8D%E5%8A%A1%E5%8F%91%E7%8E%B0)
|
||||
|
||||
# 一、服务发现架构
|
||||
|
||||
  服务发现架构通常具有下面 4 个概念:
|
||||
|
||||
1. 服务注册:服务如何使用服务发现代理进行注册?
|
||||
2. 服务地址的客户端查找:服务客户端查找服务信息的方法是什么?
|
||||
3. 信息共享:如何跨节点共享服务信息?
|
||||
4. 健康监测:服务如何将它的健康信息传回给服务发现代理?
|
||||
|
||||
下图展示了这 4 个概念的流程,以及在服务发现模式实现中通常发生的情况:
|
||||
|
||||
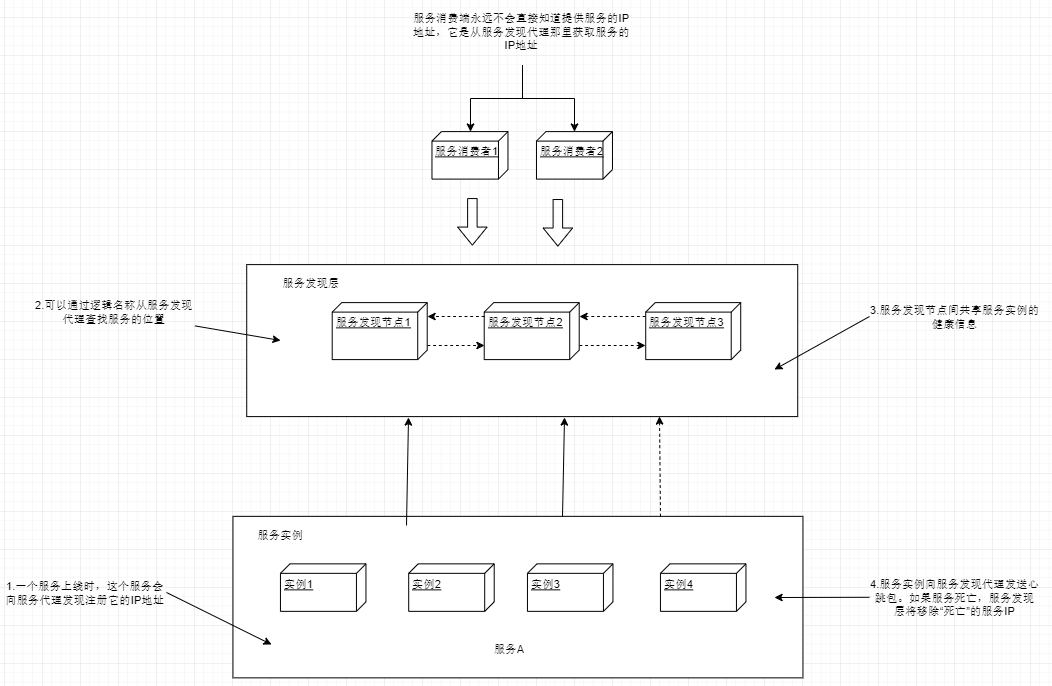
|
||||
|
||||
  通常服务实例都只向一个服务发现实例注册,服务发现实例之间再通过数据传输,让每个服务实例注册到所有的服务发现实例中。
|
||||
  服务在向服务发现实例注册后,这个服务就能被服务消费者调用了。服务消费者可以使用多种模型来"发现"服务。
|
||||
|
||||
1. 每次调用服务时,通过服务发现层来获取目标服务地址并进行调用。这种用的比较少,弊端较多。首先是每次服务调用都通过服务发现层来完成,耗时会比直接调用高。最主要的是这种方法很脆弱,消费端完全依赖于服务发现层来查找和调用服务。
|
||||
2. 更健壮的方法是使用所谓的客户端负载均衡。
|
||||
|
||||
  如下图所示:
|
||||
|
||||
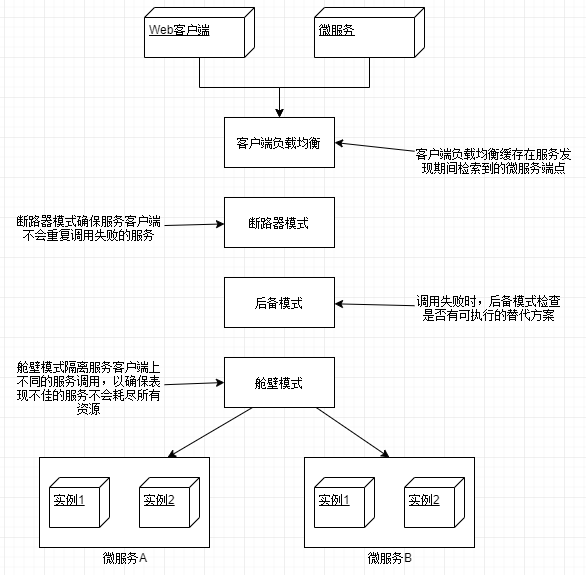
|
||||
|
||||
  在这个模型中,当服务消费者需要调用一个服务时:
|
||||
|
||||
  (1)联系服务发现层,获取所请求服务的所有服务实例,然后放到本地缓存中。
|
||||
|
||||
  (2)每次调用该服务时,服务消费者从缓存中取出一个服务实例的位置,通常这个'取出'使用简单的复制均衡算法,如“轮询”,“随机",以确保服务调用分布在所有实例之间。
|
||||
|
||||
  (3)客户端将定期与服务发现层进行通信,并刷新服务实例的缓存。
|
||||
|
||||
  (4)如果在调用服务的过程中,服务调用失败,那么本地缓存将从服务发现层中刷新数据,再次尝试。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
# 二、spring cloud 实战
|
||||
|
||||
  使用 spring cloud 和 Netflix Eureka 搭建服务发现实例。
|
||||
|
||||
## 1、构建 Spring Eureka 服务
|
||||
|
||||
  eurekasvr POM 主要配置如下:
|
||||
|
||||
```xml
|
||||
<!-- 其他依赖省略 -->
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-starter-eureka-server</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
  applicaiton.yml 配置如下:
|
||||
|
||||
```yaml
|
||||
server:
|
||||
port: 8761
|
||||
|
||||
eureka:
|
||||
client:
|
||||
#不注册自己
|
||||
register-with-eureka: false
|
||||
#不在本地缓存注册表信息
|
||||
fetch-registry: false
|
||||
server:
|
||||
#接受请求前的等待实际,开发模式下不要开启
|
||||
#wait-time-in-ms-when-sync-empty: 5
|
||||
```
|
||||
|
||||
  最后在启动类上加入注释`@SpringBootApplication`即可启动服务中心。服务中心管理页面:[http://localhost:8761](http://localhost:8761)
|
||||
|
||||
## 2、将服务注册到服务中心
|
||||
|
||||
  这里我们编写一个新服务注册到服务中心,organizationservice:组织服务。并将上一篇的两个服务:confsvr:配置中心服务,licensingservice:授权服务注册到服务中心。
|
||||
|
||||
### a、confvr 注册
|
||||
|
||||
  首先修改 POM 文件:
|
||||
|
||||
```XML
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-config-server</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-starter-eureka</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
  然后修改配置文件 application.yml:
|
||||
|
||||
```yaml
|
||||
server:
|
||||
port: 8888
|
||||
|
||||
eureka:
|
||||
instance:
|
||||
#注册服务的IP,而不是服务器名
|
||||
prefer-ip-address: true
|
||||
client:
|
||||
#向eureka注册服务
|
||||
register-with-eureka: true
|
||||
#拉取注册表的本地副本
|
||||
fetch-registry: true
|
||||
service-url:
|
||||
#Eureka服务的位置(如果有多个注册中心,使用,分隔)
|
||||
defaultZone: http://localhost:8761/eureka/
|
||||
|
||||
spring:
|
||||
profiles:
|
||||
# 使用文件系统来存储配置信息,需要设置为native
|
||||
active: native
|
||||
application:
|
||||
name: confsvr
|
||||
cloud:
|
||||
config:
|
||||
server:
|
||||
native:
|
||||
# 使用文件来存放配置文件,为每个应用程序提供用逗号分隔的文件夹列表
|
||||
searchLocations: file:///D:/configFolder/licensingservice,file:///D:/configFolder/organizationservice
|
||||
```
|
||||
|
||||
  最后在启动类加入注解`@EnableDiscoveryClient`,启动即可在 eureka 管理页面发现。
|
||||
|
||||
### b、licensingservice 注册
|
||||
|
||||
  首先修改 POM
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-starter-eureka</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-config-client</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
  然后修改配置文件 bootstrap.yml
|
||||
|
||||
```yaml
|
||||
spring:
|
||||
application:
|
||||
#指定名称,以便spring cloud config客户端知道查找哪个配置
|
||||
name: licensingservice
|
||||
profiles:
|
||||
#指定环境
|
||||
active: dev
|
||||
cloud:
|
||||
config:
|
||||
#设为true便会自动获取从配置中心获取配置文件
|
||||
enabled: true
|
||||
eureka:
|
||||
instance:
|
||||
prefer-ip-address: true
|
||||
client:
|
||||
register-with-eureka: true
|
||||
fetch-registry: true
|
||||
service-url:
|
||||
defaultZone: http://localhost:8761/eureka/
|
||||
```
|
||||
|
||||
  最后在启动类加入注解`@EnableDiscoveryClient`,启动即可在 eureka 管理页面发现本服务实例。
|
||||
|
||||
### c、创建 organizationservice
|
||||
|
||||
  首先在文件夹**file:///D:/configFolder/organizationservice**下创建两个配置文件:organizationservice.yml,organizationservice-dev.yml,内容分别为:
|
||||
|
||||
```yaml
|
||||
#organizationservice-dev.yml
|
||||
server:
|
||||
port: 10012
|
||||
```
|
||||
|
||||
```yaml
|
||||
#organizationservice.yml
|
||||
spring:
|
||||
application:
|
||||
name: organizationservice
|
||||
```
|
||||
|
||||
  主要 POM 配置如下:
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-starter-eureka</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-config-client</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
  然后修改配置文件,bootstrap.yml
|
||||
|
||||
```yaml
|
||||
spring:
|
||||
application:
|
||||
#指定名称,以便spring cloud config客户端知道查找哪个配置
|
||||
name: organizationservice
|
||||
profiles:
|
||||
#指定环境
|
||||
active: dev
|
||||
cloud:
|
||||
config:
|
||||
enabled: true
|
||||
eureka:
|
||||
instance:
|
||||
prefer-ip-address: true
|
||||
client:
|
||||
register-with-eureka: true
|
||||
fetch-registry: true
|
||||
service-url:
|
||||
defaultZone: http://localhost:8761/eureka/
|
||||
```
|
||||
|
||||
  最后在启动类加入注解`@EnableDiscoveryClient`,启动。
|
||||
|
||||
## 3、使用服务发现来查找服务
|
||||
|
||||
  现在已经有两个注册服务了,现在来让许可证服务调用组织服务,获取组织信息。首先在 organizationservice 服务中的 controller 包中加入一个 controller 类,让它能够响应请求:
|
||||
|
||||
```java
|
||||
//OrganizationController.java
|
||||
@RestController
|
||||
public class OrganizationController {
|
||||
|
||||
@GetMapping(value = "/organization/{orgId}")
|
||||
public Object getOrganizationInfo(@PathVariable("orgId") String orgId) {
|
||||
Map<String, String> data = new HashMap<>(2);
|
||||
data.put("id", orgId);
|
||||
data.put("name", orgId + "公司");
|
||||
return data;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
  接下来让许可证服务通过 Eureka 来找到组织服务的实际位置,然后调用该接口。为了达成目的,我们将要学习使用 3 个不同的 Spring/Netflix 客户端库,服务消费者可以使用它们来和 Ribbon 进行交互。从最低级别到最高级别,这些库包含了不同的与 Ribbon 进行交互的抽象封装层次:
|
||||
|
||||
- Spring DiscoveryClient
|
||||
- 启用了 RestTemplate 的 Spring DiscoveryClient
|
||||
- Neflix Feign 客户端
|
||||
|
||||
### a、使用 Spring DiscoveryClient
|
||||
|
||||
  该工具提供了对 Ribbon 和 Ribbon 中缓存的注册服务最低层次的访问,可以查询通过 Eureka 注册的所有服务以及这些服务对应的 URL。
|
||||
|
||||
  首先在 licensingservice 的启动类中加入`@EnableDiscoveryClient`注解来启用 DiscoveryClient 和 Ribbon 库。
|
||||
|
||||
  然后在 service 包下创建 OrganizationService.java
|
||||
|
||||
```java
|
||||
@Service
|
||||
public class OrganizationService {
|
||||
|
||||
private static final String SERVICE_NAME = "organizationservice";
|
||||
private DiscoveryClient discoveryClient;
|
||||
|
||||
@Autowired
|
||||
public OrganizationService(DiscoveryClient discoveryClient) {
|
||||
this.discoveryClient = discoveryClient;
|
||||
}
|
||||
|
||||
/**
|
||||
* 使用Spring DiscoveryClient查询
|
||||
*
|
||||
* @param id
|
||||
* @return
|
||||
*/
|
||||
public Organization getOrganization(String id) {
|
||||
RestTemplate restTemplate = new RestTemplate();
|
||||
List<ServiceInstance> instances = discoveryClient.getInstances(SERVICE_NAME);
|
||||
if (instances.size() == 0) {
|
||||
throw new RuntimeException("无可用的服务");
|
||||
}
|
||||
String serviceUri = String.format("%s/organization/%s", instances.get(0).getUri().toString(), id);
|
||||
ResponseEntity<Organization> responseEntity = restTemplate.exchange(serviceUri, HttpMethod.GET
|
||||
, null, Organization.class, id);
|
||||
return responseEntity.getBody();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
  接着在 controller 包中新建 LicensingController.java
|
||||
|
||||
```java
|
||||
@RestController
|
||||
public class LicensingController {
|
||||
|
||||
private OrganizationService organizationService;
|
||||
|
||||
@Autowired
|
||||
public LicensingController(OrganizationService organizationService) {
|
||||
this.organizationService = organizationService;
|
||||
}
|
||||
|
||||
@GetMapping("/licensing/{orgId}")
|
||||
public Licensing getLicensing(@PathVariable("orgId") String orgId) {
|
||||
Licensing licensing = new Licensing();
|
||||
licensing.setValid(false);
|
||||
licensing.setOrganization(organizationService.getOrganization(orgId));
|
||||
return licensing;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
  启动所有项目,访问[localhost:10011/licensing/12](localhost:10011/licensing/12),可以看到返回如下结果:
|
||||
|
||||
```json
|
||||
{
|
||||
"organization": {
|
||||
"id": "12",
|
||||
"name": "12公司"
|
||||
},
|
||||
"valid": false
|
||||
}
|
||||
```
|
||||
|
||||
  在实际开发中,基本上是用不到这个的,除非是为了查询 Ribbon 以获取某个服务的所有实例信息,才会直接使用。如果直接使用它存在以下两个问题:
|
||||
|
||||
1. 没有利用 Ribbon 的客户端负载均衡
|
||||
2. 和业务无关的代码写得太多
|
||||
|
||||
### b、使用带 Ribbon 功能的 Spring RestTemplate 调用服务
|
||||
|
||||
  这种方法是较为常用的微服务通信机制之一。要启动该功能,需要使用 Spring Cloud 注解@LoadBanced 来定义 RestTemplate bean 的构造方法。方便起见直接在启动类中定义 bean:
|
||||
|
||||
```java
|
||||
#LicensingserviceApplication.java
|
||||
@SpringBootApplication
|
||||
@EnableDiscoveryClient //使用不带Ribbon功能的Spring RestTemplate,其他情况下可删除
|
||||
public class LicensingserviceApplication {
|
||||
|
||||
/**
|
||||
* 使用带有Ribbon 功能的Spring RestTemplate,其他情况可删除
|
||||
*/
|
||||
@LoadBalanced
|
||||
@Bean
|
||||
public RestTemplate getRestTemplate(){
|
||||
return new RestTemplate();
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
SpringApplication.run(LicensingserviceApplication.class, args);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
  接着 service 包下增加一个类:OrganizationByRibbonService.java
|
||||
|
||||
```java
|
||||
@Component
|
||||
public class OrganizationByRibbonService {
|
||||
|
||||
private RestTemplate restTemplate;
|
||||
|
||||
@Autowired
|
||||
public OrganizationByRibbonService(RestTemplate restTemplate) {
|
||||
this.restTemplate = restTemplate;
|
||||
}
|
||||
|
||||
public Organization getOrganizationWithRibbon(String id) {
|
||||
ResponseEntity<Organization> responseEntity = restTemplate.exchange("http://organizationservice/organization/{id}",
|
||||
HttpMethod.GET, null, Organization.class, id);
|
||||
return responseEntity.getBody();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
  最后就是在 LicensingController.js 中加一个访问路径:
|
||||
|
||||
```java
|
||||
//不要忘记注入OrganizationByRibbonService服务
|
||||
@GetMapping("/licensingByRibbon/{orgId}")
|
||||
public Licensing getLicensingByRibbon(@PathVariable("orgId") String orgId) {
|
||||
Licensing licensing = new Licensing();
|
||||
licensing.setValid(false);
|
||||
licensing.setOrganization(organizationService.getOrganization(orgId));
|
||||
return licensing;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
  访问[localhost:10011/licensingByRibbon/113](localhost:10011/licensingByRibbon/113),即可看到结果。
|
||||
|
||||
### c、使用 Netflix Feign 客户端调用
|
||||
|
||||
  Feign 客户端是 Spring 启用 Ribbon 的 RestTemplate 类的替代方案。开发人员只需定义一个接口,然后使用 Spring 注解来标注接口,即可调用目标服务。除了编写接口定义无需编写其他辅助代码。
|
||||
|
||||
  首先启动类上加一个`@EnableFeignClients`注解启用 feign 客户端。然后在 POM 中加入 Feign 的依赖
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-starter-feign</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
  然后在 client 包下新建 OrganizationFeignClient.java
|
||||
|
||||
```java
|
||||
@FeignClient("organizationservice")//使用FeignClient注解指定目标服务
|
||||
public interface OrganizationFeignClient {
|
||||
|
||||
/**
|
||||
* 获取组织信息
|
||||
*
|
||||
* @param orgId 组织id
|
||||
* @return Organization
|
||||
*/
|
||||
@RequestMapping(method = RequestMethod.GET, value = "/organization/{orgId}", consumes = "application/json")
|
||||
Organization getOrganization(@PathVariable("orgId") String orgId);
|
||||
}
|
||||
```
|
||||
|
||||
  最后修改`LicensingController.java`,加入一个路由调用 Feign。
|
||||
|
||||
```java
|
||||
//注入OrganizationFeignClient,使用构造注入
|
||||
|
||||
@GetMapping("/licensingByFeign/{orgId}")
|
||||
public Licensing getLicensingByFeign(@PathVariable("orgId") String orgId) {
|
||||
Licensing licensing = new Licensing();
|
||||
licensing.setValid(false);
|
||||
licensing.setOrganization(organizationFeignClient.getOrganization(orgId));
|
||||
return licensing;
|
||||
}
|
||||
```
|
||||
|
||||
访问[localhost:10011/licensingByFeign/11313](localhost:10011/licensingByFeign/11313),即可看到结果。
|
||||
|
||||
# 总结
|
||||
|
||||
  这一节磨磨蹭蹭写了好几天,虽然例子很简单,但是相信应该是能够看懂的。由于篇幅原因代码没有全部贴上,想要查看完整代码,可以访问这个链接:[点击跳转](https://github.com/FleyX/demo-project/tree/master/springcloud/spring-cloud%E6%9C%8D%E5%8A%A1%E5%8F%91%E7%8E%B0)。
|
||||
|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](http://tapme.top/blog/detail/2018-11-22-15-57)
|
||||
@ -1,216 +0,0 @@
|
||||
---
|
||||
id: "2018-11-28-15-57-00"
|
||||
date: "2018/11/28 15:57:00"
|
||||
title: "springCloud学习3(Netflix Hystrix弹性客户端)"
|
||||
tags: ["spring-boot", "spring-cloud","netflix-hystrix","熔断"]
|
||||
categories:
|
||||
- "java"
|
||||
- "springCloud实战"
|
||||
---
|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](http://tapme.top/blog/detail/2018-11-28-15-57-00)
|
||||
|
||||
本次用到全部代码:[点击跳转](https://github.com/FleyX/demo-project/tree/master/springcloud/spring-cloud%E5%BC%B9%E6%80%A7%E5%AE%A2%E6%88%B7%E7%AB%AF)
|
||||
|
||||
# 一、为什么要有客户端弹性模式
|
||||
|
||||
  所有的系统都会遇到故障,分布式系统单点故障概率更高。如何构建应用程序来应对故障,是每个软件开发人员工作的关键部分。但是通常在构建系统时,大多数工程师只考虑到基础设施或关键服务彻底发生故障,使用诸如集群关键服务器、服务间的负载均衡以及异地部署等技术。尽管这些方法考虑到组件系统的彻底故障,但他们之解决了构建弹性系统的一小部分问题。当服务崩溃时,很容易检测到该服务以及失效,因此应用程序可以饶过它。然而,当服务运行缓慢时,检测到这个服务性能越发低下并绕过它是非常困难的,因为以下几个原因:
|
||||
|
||||
- 服务的降级可以是以间歇性的故障开始,并形成不可逆转的势头————可能开始只是一小部分服务调用变慢,直到突然间应用程序容器耗尽了线程(所有线程都在等待调用完成)并彻底崩溃。
|
||||
- 应用程序通常的设计是处理远程资源的彻底故障,而不是部分降级————通常,只要服务没有完全死掉,应用程序将继续调用这个服务,直到资源耗尽崩溃。
|
||||
|
||||
  性能较差的远程服务会导致很大的潜在问题,它们不仅难以检测,还会触发连锁反应,从而影响整个应用程序生态系统。如果没有适当的保护措施,一个性能不佳的服务可以迅速拖垮整个应用程序。基于云、基于微服务的应用程序特别容易受到这些类型的终端影响,因为这些应用由大量细粒度的分布式服务组成,这些服务在完成用户的事务时涉及不同的基础设施。
|
||||
|
||||
# 二、什么是客户端弹性模式
|
||||
|
||||
  客户端弹性模式是在远程服务发生错误或表现不佳时保护远程资源(另一个微服务调用或者数据库查询)免于崩溃。这些模式的目标是为了能让客户端“快速失败”,不消耗诸如数据库连接、线程池之类的资源,还可以避免远程服务的问题向客户端的消费者进行传播,引发“雪崩”效应。spring cloud 主要使用的有四种客户端弹性模式:
|
||||
|
||||
- 客户端负载均衡(client load balance)模式
|
||||
|
||||
  上一篇已经说过,这里不再赘述。
|
||||
|
||||
- 断路器(circuit breaker)模式
|
||||
|
||||
  本模式模仿的是电路中的断路器。有了软件断路器,当远程服务被调用时,断路器将监视这个调用,如果调用时间太长,断路器将介入并中断调用。此外,如果对某个远程资源的调用失败次数达到某个阈值,将会采取快速失败策略,阻止将来调用失败的远程资源。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
- 后备(fallback)模式
|
||||
|
||||
  当远程调用失败时,将执行替代代码路径,并尝试通过其他方式来处理操作,而不是产生一个异常。也就是为远程操作提供一个应急措施,而不是简单的抛出异常。
|
||||
|
||||
- 舱壁(bulkhead)模式
|
||||
|
||||
  舱壁模式是建立在造船的基础概念上。我们都知道一艘船会被划分为多个水密舱(舱壁),因而即使少数几个部位被击穿漏水,整艘船并不会被淹没。将这个概念带入到远程调用中,如果所有调用都使用的是同一个线程池来处理,那么很有可能一个缓慢的远程调用会拖垮整个应用程序。在舱壁模式中可以隔离每个远程资源,并分配各自的线程池,使之互不影响。
|
||||
|
||||
  下图展示了这些模式是如何运用到微服务中的:
|
||||
|
||||
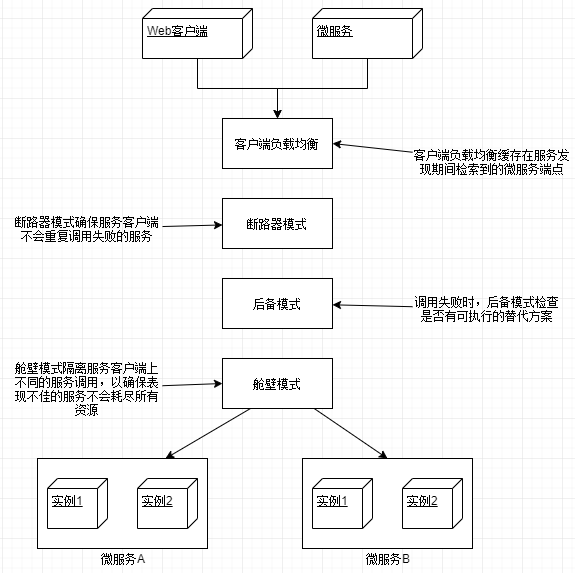
|
||||
|
||||
# 三、spring cloud 中使用
|
||||
|
||||
  使用 Netflix 的 Hystrix 库来实现上述弹性模式。继续使用上一节的项目,给 licensingservice 服务实现弹性模式。
|
||||
|
||||
## 1、代码修改
|
||||
|
||||
### 1、依赖引入
|
||||
|
||||
  首先修改 POM 文件,添加下面两个依赖:
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-starter-hystrix</artifactId>
|
||||
</dependency>
|
||||
<!--本依赖不是必须的,spring-cloud-starter-hystrix已经带了,但是在Camden.SR5发行版本中使用了1.5.6,这个版本有一个不一致的地方,在没有后备的情况下会抛出java.lang.reflect.UndeclaredThrowableException而不是com.netflix.hystrix.exception.HystrixRuntimeException,
|
||||
在后续版本中修复了这个问题-->
|
||||
<dependency>
|
||||
<groupId>com.netflix.hystrix</groupId>
|
||||
<artifactId>hystrix-javanica</artifactId>
|
||||
<version>1.5.9</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
  然后在启动类上加入`@EnableCircuitBreaker`启用 Hystrix。
|
||||
|
||||
## 2、实现断路器
|
||||
|
||||
  首先修改 organizationservice 项目中的 OrganizationController,模拟延迟,每隔两次让线程 sleep 2 秒
|
||||
|
||||
```java
|
||||
@RestController
|
||||
public class OrganizationController {
|
||||
|
||||
private static int count=1;
|
||||
|
||||
@GetMapping(value = "/organization/{orgId}")
|
||||
public Object getOrganizationInfo(@PathVariable("orgId") String orgId) throws Exception{
|
||||
if(count%2==0){
|
||||
TimeUnit.SECONDS.sleep(2);
|
||||
}
|
||||
count++;
|
||||
Map<String, String> data = new HashMap<>(2);
|
||||
data.put("id", orgId);
|
||||
data.put("name", orgId + "公司");
|
||||
return data;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
  只需在方法上添加`@HystrixCommand`,即可实现超时短路。如果 Spring 扫描到该注解注释的类,它将动态生成一个代理,来包装这个方法,并通过专门用于处理远程调用的线程池来管理对该方法的所有调用。
|
||||
|
||||
  修改 licensingservice 服务中的 OrganizationByRibbonService,OrganizationFeignClient,给其中的方法加上`@HystrixCommand`的注解。然后再访问接口[localhost:10011/licensingByRibbon/11313](localhost:10011/licensingByRibbon/11313),[localhost:10011/licensingByFeign/11313](localhost:10011/licensingByFeign/11313)。多次访问可发现抛出错误`com.netflix.hystrix.exception.HystrixRuntimeException`,断路器生效,默认情况下操时时间为 1s。
|
||||
|
||||
```json
|
||||
{
|
||||
"timestamp": 1543823192424,
|
||||
"status": 500,
|
||||
"error": "Internal Server Error",
|
||||
"exception": "com.netflix.hystrix.exception.HystrixRuntimeException",
|
||||
"message": "OrganizationFeignClient#getOrganization(String) timed-out and no fallback available.",
|
||||
"path": "/licensingByFeign/11313/"
|
||||
}
|
||||
```
|
||||
|
||||
  可通过设置注解参数来修改操时时间。设置超时时间大于 2s 后便不会报操时错误。(不知道为什么在 Feign 中设置失败,ribbon 中正常。)。一般都是将配置写在配置文件中。
|
||||
|
||||
```java
|
||||
@HystrixCommand(commandProperties = {
|
||||
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "20000")
|
||||
})
|
||||
```
|
||||
|
||||
## 3、后备处理
|
||||
|
||||
  由于远程资源的消费者和资源本身之间存在存在一个"中间人",因此开发人员能够拦截服务故障,并选择替代方案。在 Hystrix 中进行后备处理,非常容易实现。
|
||||
|
||||
1. 在 ribbon 中的实现
|
||||
|
||||
  只需在`@HystrixCommand`注解中加入属性 fallbackMethod="methodName",那么在执行失败时,便会执行后备方法。注意防备方法必须和被保护方法在同一个类中,并且方法签名必须相同。修改 licensingservice 中 service 包下的 OrganizationByRibbonService 类,改为如下:
|
||||
|
||||
```java
|
||||
@Component
|
||||
public class OrganizationByRibbonService {
|
||||
|
||||
private RestTemplate restTemplate;
|
||||
|
||||
|
||||
@Autowired
|
||||
public OrganizationByRibbonService(RestTemplate restTemplate) {
|
||||
this.restTemplate = restTemplate;
|
||||
}
|
||||
|
||||
@HystrixCommand(commandProperties = {
|
||||
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "1000")
|
||||
},fallbackMethod = "getOrganizationWithRibbonBackup")
|
||||
public Organization getOrganizationWithRibbon(String id) throws Exception {
|
||||
ResponseEntity<Organization> responseEntity = restTemplate.exchange("http://organizationservice/organization/{id}",
|
||||
HttpMethod.GET, null, Organization.class, id);
|
||||
return responseEntity.getBody();
|
||||
}
|
||||
|
||||
public Organization getOrganizationWithRibbonBackup(String id)throws Exception{
|
||||
Organization organization = new Organization();
|
||||
organization.setId("0");
|
||||
organization.setName("组织服务调用失败");
|
||||
return organization;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
  启动应用,多次访问[localhost:10011/licensingByRibbon/11313/](localhost:10011/licensingByRibbon/11313/),可以发现调用失败时,会启用后备方法。
|
||||
|
||||
2. 在 feign 中实现
|
||||
|
||||
  在 feign 中实现后备模式,需要编写一个 feign 接口的实现类,然后在 feign 接口中指定该类。以 licensingservice 为例。首先在 client 包中添加一个 OrganizationFeignClientImpl 类,代码如下:
|
||||
|
||||
```java
|
||||
@Component
|
||||
public class OrganizationFeignClientImpl implements OrganizationFeignClient{
|
||||
|
||||
@Override
|
||||
public Organization getOrganization(String orgId) {
|
||||
Organization organization=new Organization();
|
||||
organization.setId("0");
|
||||
organization.setName("后备模式返回的数据");
|
||||
return organization;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
然后修改 OrganizationFeignClient 接口的注解,将`@FeignClient("organizationservice")`改为`@FeignClient(name="organizationservice",fallback = OrganizationFeignClientImpl.class`。
|
||||
|
||||
  重启项目,多次访问[localhost:10011/licensingByFeign/11313/](localhost:10011/licensingByFeign/11313/),可发现后备服务起作用了。
|
||||
|
||||
  在确认是否要启用后备服务时,要注意以下两点:
|
||||
|
||||
- 后备是一种在资源操时或失败时提供行动方案的机制。如果只是用后备来捕获操时异常然后只做日志记录,那只需要 try..catch 即可,捕获 HystrixRuntimeException 异常。
|
||||
|
||||
- 注意后备方法所执行的操作。如果在后备服务中调用另一个分布式服务,需要注意用@HystrixCommand 方法注解包装后备方法。
|
||||
|
||||
## 4、实现舱壁模式
|
||||
|
||||
  在基于微服务的应用程序中,通常需要调用多个微服务来完成特定的任务,在不适用舱壁的模式下,这些调用默认是使用同一批线程来执行调用的,而这些线程是为了处理整个 Java 容器的请求而预留的。因此在存在大量请求的情况下,一个服务出现性能问题会导致 Java 容器内的所有线程被占用,同时阻塞新请求,最终容器彻底崩溃。
|
||||
|
||||
  Hystrix 使用线程池来委派所有对远程服务的调用,默认情况下这个线程池有 10 个工作线程。但是这样很容易出现一个运行缓慢的服务占用全部的线程,所有 hystrix 提供了一种一种易于使用的机制,在不同的远程资源调用间创建‘舱壁’,将不同服务的调用隔离到不同的线程池中,使之互不影响。
|
||||
|
||||
  要实现隔离的线程池,只需要在`@HystrixCommand`上加入线程池的注解,这里以 ribbon 为例(Feign 类似)。修改 licensingservice 中 service 包下的 OrganizaitonByRibbonService 类,将`getOrganizationWithRibbon`方法的注解改为如下:
|
||||
|
||||
```java
|
||||
@HystrixCommand(commandProperties = {
|
||||
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "1000")
|
||||
}, fallbackMethod = "getOrganizationWithRibbonBackup",
|
||||
threadPoolKey = "licenseByOrgThreadPool",
|
||||
threadPoolProperties = {
|
||||
@HystrixProperty(name = "coreSize", value = "30"),
|
||||
@HystrixProperty(name = "maxQueueSize", value = "10")
|
||||
})
|
||||
```
|
||||
|
||||
如果将`maxQueueSize`属性值设为-1,将使用`SynchronousQueue`保存所有的传入请求,同步队列会强制要求正在处理中的请求数量永远不能超过线程池的大小。设为大于 1 的值将使用`LinkedBlockingQueue`。
|
||||
|
||||
  **注意**:示例代码中都是硬编码属性值到 Hystrix 注解中的。在实际应用环境中,一般都是将配置项配置在 Spring Cloud Config 中的,方便统一管理。
|
||||
|
||||
本次用到全部代码:[点击跳转](https://github.com/FleyX/demo-project/tree/master/springcloud/spring-cloud%E5%BC%B9%E6%80%A7%E5%AE%A2%E6%88%B7%E7%AB%AF)
|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](tapme.top/blog/detail/2018-11-28-15-57-00)
|
||||
@ -1,446 +0,0 @@
|
||||
---
|
||||
id: "2019-01-03-19-19"
|
||||
date: "2019/01/03 19:19"
|
||||
title: "springCloud学习4(Zuul服务路由)"
|
||||
tags: ["spring-boot", "spring-cloud","netflix-zuul","service-gateway"]
|
||||
categories:
|
||||
- "java"
|
||||
- "springCloud实战"
|
||||
---
|
||||
|
||||
镇博图
|
||||

|
||||
|
||||
**本篇代码存放于:**[github](https://github.com/FleyX/demo-project/tree/master/springcloud/spring-cloud%E6%9C%8D%E5%8A%A1%E8%B7%AF%E7%94%B1)
|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](http://tapme.top/blog/detail/2019-01-03-19-19)
|
||||
|
||||
**本篇中 Zuul 版本为 1.x,目前最新的是 2.x,二者在过滤器的使用上有较大区别**
|
||||
|
||||
**超长警告**
|
||||
|
||||
# 一、背景
|
||||
|
||||
  微服务架构将一个应用拆分为很多个微小应用,这样会导致之前不是问题的问题出现,比如:
|
||||
|
||||
1. 安全问题如何实现?
|
||||
2. 日志记录如何实现?
|
||||
3. 用户跟踪如何实现?
|
||||
|
||||
上面的问题在传统的单机应用很容易解决,只需要当作一个功能实现即可。但是在微服务中就行不通了,让每个服务都实现一份上述功能,那是相当不现实的,费时,费力还容易出问题。
|
||||
|
||||
  为了解决这个问题,需要将这些横切关注点(分布式系统级别的横切关注点和 spring 中的基本一个意思)抽象成一个独立的且作为应用程序中所有微服务调用的过滤器和路由器的服务。这样的服务被称为——**服务网管(service gateway)**,服务客户端不再直接调用服务。取而代之的是,服务网关作为单个策略执行点(Policy Enforcement Point,PEP) , 所有调用都通过服务网管进行路由,然后送到目的地。
|
||||
|
||||
# 二、服务网关
|
||||
|
||||
## 1、什么是服务网关
|
||||
|
||||
  之前的几节中我们是通过 http 请求直接调用各个服务,通常在实际系统中不会直接调用。而是通过服务网关来进行服务调用。服务网关充当了服务客户端和被调用服务间的中介。服务客户端仅与服务网关管理的单个 url 进行对话。下图说了服务网关在一个系统中的作用:
|
||||
|
||||
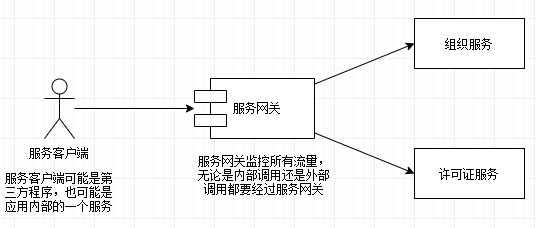
|
||||
|
||||
服务网关位于服务客户端和相应的服务实例之间。所有的服务调用(内部和外部)都应流经服务网关。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
## 2、功能
|
||||
|
||||
  由于服务网关代理了所有的服务调用,**因此它还能充当服务调用的中央策略执行点(PEP)**,通俗的说就能能够在此实现横切关注点,不用在各个微服务中实现。主要有以下几个:
|
||||
|
||||
- **静态路由**——服务网关将所有的服务调用放置在单个 URL 和 API 路由后,每个服务对应一个固定的服务端点,方便开发人员的服务调用。
|
||||
|
||||
- **动态路由**——服务网关可以检测传入的请求,根据请求数据和请求者执行职能路由。比如将一部分的调用路由到特定的服务实例上,比如测试版本。
|
||||
|
||||
- **验证和授权**——所有服务调用都经过服务网关,显然可以在此进行权限验证,确保系统安全。
|
||||
|
||||
- **日志记录**——当服务调用经过服务网关时,可以使用服务网关来收集数据和日志信息(比如服务调用次数,服务响应时间等)。还能确保在用户请求上提供关键信息以确保日志统计(比如给每个用户请求加一个 url 参数,每个服务中可通过该参数将关键信息对应到某个用户请求)。
|
||||
|
||||
**_看到这儿可能会有这样的疑问:所有调用都通过服务网关,难道服务网关不是单点故障和潜在瓶颈吗?_**
|
||||
|
||||
_1. 在单独的服务器前,负载均衡器是很有用的。将负载均衡器放到多个服务网关前面是比较好的设计,确保服务网关可以实现伸缩。但是如果将负载均衡器置于所有服务前便不是一个好主意,会造成瓶颈。_
|
||||
|
||||
_2. 服务网关的代码应该是无状态的。有状态的应用实现伸缩性较为麻烦_
|
||||
|
||||
_3. 服务网关的代码应该轻量的。服务网关是服务调用的“阻塞点”,不易在服务网关处耽误较长的时间,比如进行同步数据库操作_
|
||||
|
||||
# 三、实战
|
||||
|
||||
  使用 Netflix Zuul 来构建服务网关,配合之前的代码,让服务网关来管理服务调用。
|
||||
|
||||
_在生产环境中不建议使用 zuul,该组件性能较弱,且已经停止更新_
|
||||
|
||||
## 1、创建 zuulsvr 项目
|
||||
|
||||
  详细过程不赘述,和之前一样(注意 spring cloud 版本要和之前一致),主要 pom 依赖如下:
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-starter-zuul</artifactId>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-starter-eureka</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
## 2、配置 zuul
|
||||
|
||||
  首先在启动加入注解开启 zuul 并注册到 eureka 中
|
||||
|
||||

|
||||
|
||||
  然后编写配置文件:
|
||||
|
||||
```yaml
|
||||
spring:
|
||||
application:
|
||||
name: zuulservice
|
||||
#服务发现配置
|
||||
eureka:
|
||||
instance:
|
||||
prefer-ip-address: true
|
||||
client:
|
||||
register-with-eureka: true
|
||||
fetch-registry: true
|
||||
service-url:
|
||||
defaultZone: http://localhost:8761/eureka/
|
||||
server:
|
||||
port: 5555
|
||||
```
|
||||
|
||||
这样便以默认配置启动了 zuul 服务网关。
|
||||
|
||||
## 3、路由配置
|
||||
|
||||
  Zuul 核心就是一个反向代理。在微服务架构下,Zuul 从客户端接受微服务调用并将其转发给下游服务。要和下游服务进行沟通,Zuul 必须知道如何将进来的调用映射到下游路由中。Zuul 有一以下几种路由机制:
|
||||
|
||||
- 通过服务发现自动映射路由
|
||||
- 通过服务发现手动映射路由
|
||||
- 使用静态 URL 手动映射
|
||||
|
||||
### 1)、服务发现自动映射
|
||||
|
||||
默认情况下,Zuul 根据服务 ID 来进行自动路由。先将组织服务中的延时去掉
|
||||
|
||||

|
||||
|
||||
启动之前的所有服务实例,然后通过 postman 访问[localhost:5555/organizationservice/organization/12](localhost:5555/organizationservice/organization/12),得到结果如下:
|
||||
|
||||
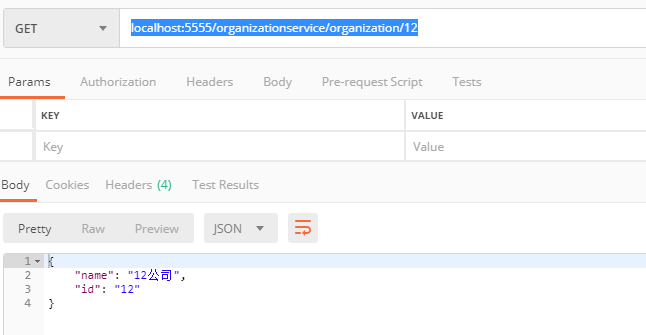
|
||||
|
||||
说明服务网关自动路由成功。
|
||||
|
||||
  如果要查看 Zuul 服务器管理的路由,可以通过访问 Zuul 服务器上的/routes,返回结果如下:
|
||||
|
||||
```json
|
||||
{
|
||||
"/confsvr/**": "confsvr",
|
||||
"/licensingservice/**": "licensingservice",
|
||||
"/organizationservice/**": "organizationservice"
|
||||
}
|
||||
```
|
||||
|
||||
左边的路由由基于 Eureka 的服务 ID 自动创建的,右边为路由所有映射的 Eureka 服务 ID。
|
||||
|
||||
### 2)、服务发现手动手动
|
||||
|
||||
  如果觉得自动路由不好用,我们还可以更细粒度地明确定义路由映射。例如想要缩短组织服务名称来简化路由,可在`application.yml`配置中定义路由映射,在配置文件中加入如下配置:
|
||||
|
||||
```
|
||||
zuul:
|
||||
routes:
|
||||
organizationservice: /org/**
|
||||
```
|
||||
|
||||
  上面的配置将**org**开头的路径映射到组织服务上了。重启服务器,访问[localhost:5555/org/organization/12](localhost:5555/org/organization/12),仍然能够获取到数据。
|
||||
|
||||
  现在访问`/routes`端点可以看到如下结果:
|
||||
|
||||
```json
|
||||
{
|
||||
"/org/**": "organizationservice",
|
||||
"/confsvr/**": "confsvr",
|
||||
"/licensingservice/**": "licensingservice",
|
||||
"/organizationservice/**": "organizationservice"
|
||||
}
|
||||
```
|
||||
|
||||
可以看到不光有自定义的组织路由,自动映射的组织路由也存在,如果想要排除自动映射的路由可配置`ignored-services`属性,用法如下:
|
||||
|
||||
```yaml
|
||||
zuul:
|
||||
routes:
|
||||
organizationservice: /org/**
|
||||
# 使用","分隔,“*”表示全部忽略
|
||||
ignored-services: 'organizationservice'
|
||||
```
|
||||
|
||||
  服务网关有一种常见模式是通过使用`/api`之类的标记来为所有服务调用添加前缀,可通过配置`prefix`属性来支持。用法如下:
|
||||
|
||||
```yaml
|
||||
zuul:
|
||||
routes:
|
||||
organizationservice: /org/**
|
||||
# 使用","分隔,“*”表示全部忽略
|
||||
ignored-services: 'organizationservice'
|
||||
prefix: /api
|
||||
```
|
||||
|
||||
配置后再次访问`/routes`端点可以看到路径前都加上了`/api`
|
||||
|
||||
### 3)、静态 URL 手动映射
|
||||
|
||||
  如果系统系统中还存在一些不受 Eureka 管理的服务,可以建立 Zuul 直接路由到一个静态定义的 URL。假设许可证服务是其他语言编写的 web 项目,并且希望通过 Zuul 来代理,可这样配置:
|
||||
|
||||
```yaml
|
||||
zuul:
|
||||
routes:
|
||||
#用于内部识别关键字
|
||||
licensestatic:
|
||||
path: /licensestatic/**
|
||||
url: http://localhost:8091
|
||||
```
|
||||
|
||||
配置完成后重启 zuul 访问`/routes`端点如下所示,静态路由已经加入:
|
||||
|
||||
```json
|
||||
{
|
||||
"/api/licensestatic/**": "http://localhost:8091",
|
||||
"/api/org/**": "organizationservice",
|
||||
"/api/confsvr/**": "confsvr",
|
||||
"/api/licensingservice/**": "licensingservice",
|
||||
"/api/zuulservice/**": "zuulservice"
|
||||
}
|
||||
```
|
||||
|
||||
  licensestatic 端点不再使用 Eureka,直接将请求路由到`localhost:8091`。但是这里存在一个问题,如果许可证服务有多个实例,该如何用到负载均衡?这里只能配置一条路径指向请求。这里又有一个配置项来禁用 Ribbon 与 Eureka 集成,然后列出许可证服务的所有实例,配置如下:
|
||||
|
||||
```yaml
|
||||
#zuul配置
|
||||
zuul:
|
||||
routes:
|
||||
#用于内部识别关键字
|
||||
licensestatic:
|
||||
path: /licensestatic/**
|
||||
serviceId: licensestatic
|
||||
organizationservice: /org/**
|
||||
# 使用","分隔,“*”表示全部忽略
|
||||
ignored-services: 'organizationservice'
|
||||
prefix: /api
|
||||
|
||||
ribbon:
|
||||
eureka:
|
||||
#禁用Eureka支持
|
||||
enabled: false
|
||||
|
||||
licensestatic:
|
||||
ribbon:
|
||||
#licensestatic服务将会路由到下列地址
|
||||
listOfServers: http://localhost:10011,http://localhost:10012
|
||||
```
|
||||
|
||||
配置完毕后,访问`/routes`端点发现`licensestatic/**`映射到了 licensestatic 服务上,相当于 Zuul 模拟了一个服务出来。但是 Eureka 上是没有这个服务的,所以需要禁用掉 Ribbon 的 Eureka 支持,不然是无法访问成功的(Ribbon 向 Eureka 查询该服务不存在,报错)。现在 x=连续访问[localhost:5555//api/licensestatic/licensing/12](localhost:5555//api/licensestatic/licensing/12),可以发现正常响应和 404 交替出现(10011 上能否访问成功,10012 报错 404),说明配置的多个地址生效了。
|
||||
|
||||
**_问题又来了_**
|
||||
|
||||
  _禁用eureka支持会导致所有服务的地址都需要手动指定,ribbon不会再从eureka中获取服务实例信息。所以没办法混合使用_
|
||||
|
||||
  目前有两种办法来规避这个问题:
|
||||
|
||||
1. 对于不能用 Eureka 管理的应用,可以建立一个单独的 Zuul 服务器来处理这些路由。
|
||||
|
||||
2. 建立一个 Spring Cloud Sidecar 实例。Spring Cloud Sidecar 允许开发使用 Eureka 实例注册非 JVM 服务,然后再通过 Zuul 代理,相当于**曲线救国**。
|
||||
|
||||
## 4、动态重载路由
|
||||
|
||||
  zuul 还有一个动态加载路由的功能,也就是在不重启 zuul 服务的情况下刷新路由。
|
||||
|
||||
  直接修改`application.yml`将 prefix 从`/api`改为`/apis`。**注意这里修改后要让修改生效需编译一次 application.yml 让修改替换到 target 文件中(idea 如此,eclipse 应该类似),或者直接到编译文件夹下修改 application.yml**
|
||||
|
||||
  然后访问`/refresh`路径,可以看到如下返回值:
|
||||
|
||||
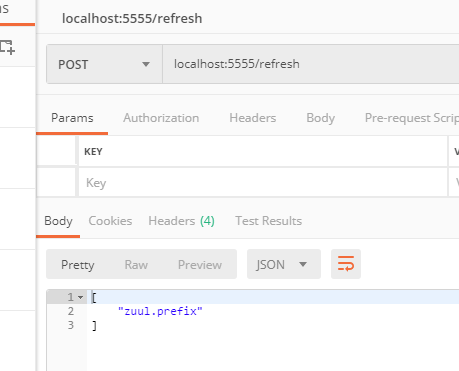
|
||||
|
||||
响应表明更新 prefix。然后访问`/routes`路径会发现前缀变成了**apis**
|
||||
|
||||
  这个功能与 spring cloud config 配合,用起来就是爽。
|
||||
|
||||
## 5、服务超时
|
||||
|
||||
  Zuul 使用 Netflix 的 Hystrix 和 Ribbon 库来进行 http 请求。so 也是有超时机制存在的。配置方法和前面的一篇类似。但是只能通过配置文件来进行,无法通过注解(这是 Zuul 管理的没有地方给你写注解)。通过配置`hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds`属性来实现。如果要为特定的服务配置只需将 default 替换为服务名就行了。
|
||||
|
||||
**注意**还要只有有另一个超时机制。虽然覆盖了 hystrix 的超时,但是 Ribbon 也会超时任何超过 5s 的调用。so 如果超时时间大于 5s 还要配置 Ribbon 的超时,配置方式如下:
|
||||
|
||||
```yaml
|
||||
#对所有服务生效
|
||||
ribbon.readTimeout: 7000
|
||||
#对组织服务生效
|
||||
licensingservice.ribbon.readTimeout: 7000
|
||||
```
|
||||
|
||||
## 6、重点:过滤器
|
||||
|
||||
  这才是服务网关真正重要的东西。有了过滤器才能实现自定义的通用处理逻辑。可在此进行通用的**安全验证**、**日志**、**服务跟踪**等操作。和 springboot 中的过滤器概念类似,这里就不做说明了。
|
||||
|
||||
  Zuul 支持以下四种过滤器:
|
||||
|
||||
- **前置过滤器**——在将请求发送到目的地之前被调用。通常进行请求格式检查、身份验证等操作。
|
||||
|
||||
- **后置过滤器**——在目标服务被调用被将响应发回调用者后被调用。通常用于记录从目标服务返回的响应、处理错误或审核敏感信息。
|
||||
|
||||
- **路由过滤器**——在目标服务被调用之前拦截调用。通常用来做动态路由。
|
||||
|
||||
- **错误过滤器**——在产生错误是调用,用于对错误进行统一处理。
|
||||
|
||||
下图展示了在处理客户端请求时,各种过滤器时如何工作的:
|
||||
|
||||
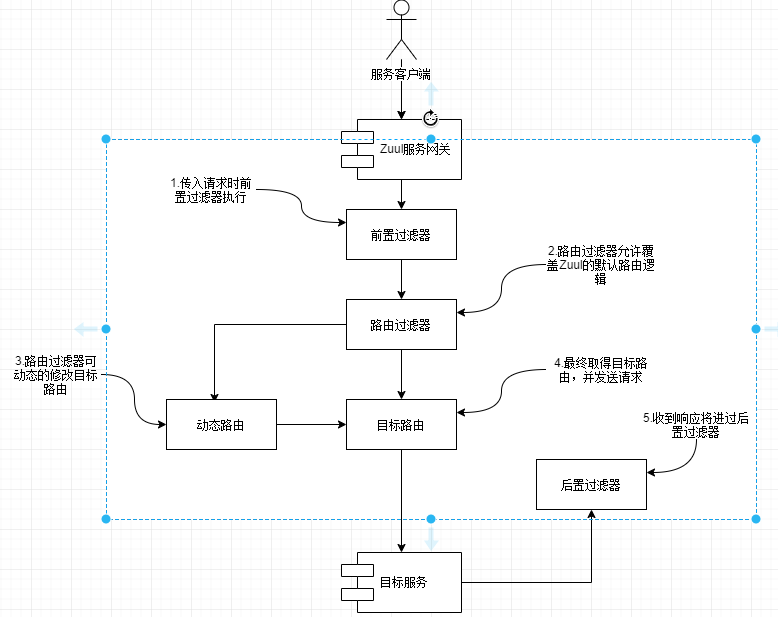
|
||||
|
||||
下面说说如何来使用这些过滤器:
|
||||
|
||||
### a、前置过滤器
|
||||
|
||||
  这里我们来实现一个过滤器-IdFilter,对每个请求检查请求头中是否有一个关联 id,无 id 生成一个 id 加入到 header 中。代码如下:
|
||||
|
||||
```java
|
||||
@Component
|
||||
public class IdFilter extends ZuulFilter {
|
||||
|
||||
private static final Logger LOGGER = LoggerFactory.getLogger(IdFilter.class);
|
||||
|
||||
/**
|
||||
* 返回过滤器类型 ;pre:前置过滤器。post:后置过滤器。routing:路由过滤器。error:错误过滤器
|
||||
*/
|
||||
@Override
|
||||
public String filterType() {
|
||||
return "pre";
|
||||
}
|
||||
|
||||
/**
|
||||
* 过滤器执行顺序
|
||||
*/
|
||||
@Override
|
||||
public int filterOrder() {
|
||||
return 1;
|
||||
}
|
||||
|
||||
/**
|
||||
* 是否启动此过滤器
|
||||
*/
|
||||
@Override
|
||||
public boolean shouldFilter() {
|
||||
return true;
|
||||
}
|
||||
|
||||
@Override
|
||||
public Object run() {
|
||||
RequestContext ctx = RequestContext.getCurrentContext();
|
||||
String id = ctx.getRequest().getHeader("id");
|
||||
//如果request找不到,再到zuul的方法中找id.request不允许直接修改response中的header,
|
||||
// 所以为了让后续的过滤器能够获取到id才有下面的语法
|
||||
if(id==null){
|
||||
id = ctx.getZuulRequestHeaders().get("id");
|
||||
}
|
||||
if (id == null) {
|
||||
id = UUID.randomUUID().toString();
|
||||
LOGGER.info("{} 无id,生成id:{}",ctx.getRequest().getRequestURI(), id);
|
||||
ctx.addZuulRequestHeader("id", id);
|
||||
} else {
|
||||
LOGGER.info("{}存在id:{}", ctx.getRequest().getRequestURI(), id);
|
||||
}
|
||||
return null;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
要在 Zuul 中实现过滤器,必须拓展 ZuulFilter 类(2.x 版本中不是这样的),然后覆盖上述 4 个方法。
|
||||
|
||||
  要给请求头加入一个 header 需要在`ctx.addZuulRequestHreader("","")`(上面代码中的 RequestContext 是 zuul 重写的,在其中加入了一些方法)方法中操作,zuul 会在发出请求是把 header 加到请求头中。(因为 Zuul 本质是一个代理,它截取请求,然后自己再发送这个请求,所有不能也没有必要在原来的 request 上加 header。
|
||||
|
||||
  重启项目 Zuul,访问`localhost:5555/apis/licensestatic/licensing/12`,可以看到控制台有如下打印:
|
||||
|
||||

|
||||
|
||||
说明前置过滤器生效。
|
||||
|
||||
  现在从 zuul 服务网关发往许可证服务的 http 请求已经携带了 id。
|
||||
|
||||
|
||||
### b、后置过滤器
|
||||
|
||||
  后置过滤器通常用于进行敏感信息过滤和响应记录。这里我们实现一个后置过滤器,将许可证服务请求的响应内容打印到控制台上同时把`id`header 插入到服务客户端请求的 response 中。
|
||||
|
||||
```java
|
||||
@Component
|
||||
public class ResponseFilter extends ZuulFilter {
|
||||
|
||||
private static final Logger LOGGER = LoggerFactory.getLogger(ResponseFilter.class);
|
||||
|
||||
/**
|
||||
* 返回过滤器类型 ;pre:前置过滤器。post:后置过滤器。routing:路由过滤器。error:错误过滤器
|
||||
*/
|
||||
@Override
|
||||
public String filterType() {
|
||||
return "post";
|
||||
}
|
||||
|
||||
/**
|
||||
* 过滤器执行顺序
|
||||
*/
|
||||
@Override
|
||||
public int filterOrder() {
|
||||
return 1;
|
||||
}
|
||||
|
||||
/**
|
||||
* 是否启动此过滤器
|
||||
*/
|
||||
@Override
|
||||
public boolean shouldFilter() {
|
||||
return true;
|
||||
}
|
||||
|
||||
@Override
|
||||
public Object run(){
|
||||
RequestContext ctx = RequestContext.getCurrentContext();
|
||||
String id = ctx.getZuulRequestHeaders().get("id");
|
||||
ctx.getResponse().addHeader("id", id);
|
||||
try {
|
||||
BufferedReader reader = new BufferedReader(new InputStreamReader(ctx.getResponseDataStream()));
|
||||
String response = reader.readLine();
|
||||
LOGGER.info("响应为:{}", response);
|
||||
//写到输出流中,本来可以由zuul框架来操作,但是我们已经读取了输入流,zuul读不到数据了,所以要手动写响应到response
|
||||
ctx.getResponse().setHeader("Content-Type","application/json;charset=utf-8");
|
||||
ctx.getResponse().getWriter().write(response);
|
||||
} catch (Exception e) {
|
||||
}
|
||||
return null;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
经过这样一波操作,就能达到目的了。访问:[localhost:5555/apis/licensestatic/licensing/12](http://localhost:5555/apis/licensestatic/licensing/12)。控制台打印如下:
|
||||
|
||||

|
||||
|
||||
请求响应如下:
|
||||
|
||||
|
||||
|
||||
### c、路由过滤器
|
||||
|
||||
  路由过滤器用起来有点复杂,这里不写具体的实际代码,只是写一个思路。具体代码可以参考[spring 微服务](https://github.com/carnellj/spmia-chapter6/blob/master/zuulsvr/src/main/java/com/thoughtmechanix/zuulsvr/filters/SpecialRoutesFilter.java)
|
||||
|
||||
1. 获取当前请求路径
|
||||
2. 判断是否需要进行特殊路由
|
||||
3. 如需要进行特殊路由,在此进行 http 调用
|
||||
4. 将 http 调用的 response 写入到当前请求的 response 中
|
||||
|
||||
# 结束
|
||||
|
||||
  终于写完了,微服务的基础学习又近了一步,加油!
|
||||
|
||||
**本篇代码存放于:**[github](https://github.com/FleyX/demo-project/tree/master/springcloud/spring-cloud%E6%9C%8D%E5%8A%A1%E8%B7%AF%E7%94%B1)
|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](tapme.top/blog/detail/2019-01-03-19-19)
|
||||
@ -1,352 +0,0 @@
|
||||
---
|
||||
id: "2019-01-03-19-19"
|
||||
date: "2019/01/03 19:19"
|
||||
title: "springCloud学习5(Spring-Cloud-Stream事件驱动)"
|
||||
tags:
|
||||
["spring-boot", "spring-cloud", "spring-cloud-stream", "kafka", "事件驱动"]
|
||||
categories:
|
||||
- "java"
|
||||
- "springCloud实战"
|
||||
---
|
||||
|
||||

|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](http://tapme.top/blog/detail/2019-01-03-19-19)
|
||||
|
||||
**本篇所用全部代码:**[FleyX 的 github](https://github.com/FleyX/demo-project/tree/master/springcloud/spring-cloud-stream%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97)
|
||||
|
||||
  想想平常生活中做饭的场景,在用电饭锅做饭的同时,我们可以洗菜、切菜,等待电饭锅发出饭做好的提示我们回去拔下电饭锅电源(或者什么也不知让它处于保温状态),反正这个时候我们知道饭做好了,接下来可以炒菜了。从这里可以看出我们在日常生活中与世界的互动并不是同步的、线性的,不是简单的请求--响应模型。它是事件驱动的,我们不断的发送消息、接受消息、处理消息。
|
||||
|
||||
  同样在软件世界中也不全是请求--响应模型,也会需要进行异步的消息通信。使用消息实现事件通信的概念被称为消息驱动架构(Event Driven Architecture,EDA),也被称为消息驱动架构(Message Driven Architecture,MDA)。使用这类架构可以构建高度解耦的系统,该系统能够对变化做出响应,且不需要与特定的库或者服务紧密耦合。
|
||||
|
||||
  在 Spring Cloud 项目中可以使用**Spirng Cloud Stream**轻而易举的构建基于消息传递的解决方案。
|
||||
|
||||
# 为什么使用消息传递
|
||||
|
||||
  要解答这个问题,让我们从一个例子开始,之前一直使用的两个服务:许可证服务和组织服务。每次对许可证服务进行请求,许可证服务都要通过 http 请求到组织服务上查询组织信息。显而易见这次额外的 http 请求会花费较长的时间。如果能够将缓存组织数据的读操作,将会大幅提高许可证服务的响应时间。但是缓存数据有如下 2 个要求:
|
||||
|
||||
- **缓存的数据需要在许可证服务的所有实例之间保存一致**——这意味着不能将数据缓存到服务实例的内存中。
|
||||
- **在更新或者删除一个组织数据时,许可证服务缓存的数据需要失效**——避免读取到过期数据,需要尽早让过时数据失效并删除。
|
||||
|
||||
  要实现上面的要求,现在有两种办法。
|
||||
|
||||
1. 使用同步请求--响应模型来实现。组织服务在组织数据变化时调用许可证服务的接口通知组织服务已经变化,或者直接操作许可证服务的缓存。
|
||||
|
||||
2. 使用事件驱动。组织服务发出一个异步消息。许可证服务收到该消息后清除对应的缓存。
|
||||
|
||||
## 同步请求-响应方式
|
||||
|
||||
  许可证服务在 redis 中缓存从组织服务中查询到的服务信息,当组织数据更新时,组织服务同步 http 请求通知许可证服务数据过期。这种方式有以下几个问题:
|
||||
|
||||
- 组织服务和许可证服务紧密耦合
|
||||
- 这种方式不够灵活,如果要为组织服务添加新的消费者,必须修改组织服务代码,以让其通知新的服务数据变动。
|
||||
|
||||
## 使用消息传递方式
|
||||
|
||||
  同样的许可证服务在 redis 中缓存从组织服务中查询到的服务信息,当组织数据更新时,组织服务将更新信息写入到队列中。许可证服务监听消息队列。使用消息传递有一下 4 个好处:
|
||||
|
||||
- 松耦合性:将服务间的依赖,变成了服务对队列的依赖,依赖关系变弱了。
|
||||
- 耐久性:即使服务消费者已经关闭了,也可以继续往里发送消息,等消费者开启后处理
|
||||
- 可伸缩性: 消息发送者不用等待消息消费者的响应,它们可以继续做各自的工作
|
||||
- 灵活性:消息发送者不用知道谁会消费这个消息,因此在有新的消息消费者时无需修改消息发送代码
|
||||
|
||||
# spring cloud 中使用消息传递
|
||||
|
||||
  spring cloud 项目中可以通过 spring cloud stream 框架来轻松集成消息传递。该框架最大的特点是抽象了消息传递平台的细节,因此可以在支持的消息队列中随意切换(包括 Apache Kafka 和 RabbitMQ)。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
## spring cloud stream 架构
|
||||
|
||||
  spring cloud stream 中有 4 个组件涉及到消息发布和消息消费,分别为:
|
||||
|
||||
1. 发射器<br/>
|
||||
  当一个服务准备发送消息时,它将使用发射器发布消息。发射器是一个 Spring 注解接口,它接收一个普通 Java 对象,表示要发布的消息。发射器接收消息,然后序列化(默认序列化为 JSON)后发布到通道中。
|
||||
|
||||
2. 通道<br/>
|
||||
  通道是对队列的一个抽象。通道名称是与目标队列名称相关联的。但是队列名称并不会直接公开在代码中,代码永远只会使用通道名。
|
||||
|
||||
3. 绑定器<br/>
|
||||
  绑定器是 spring cloud stream 框架的一部分,它是与特定消息平台对话的 Spring 代码。通过绑定器,使得开发人员不必依赖于特定平台的库和 API 来发布和消费消息。
|
||||
|
||||
4. 接收器<br/>
|
||||
  服务通过接收器来从队列中接收消息,并将消息反序列化。
|
||||
|
||||
处理逻辑如下:
|
||||
|
||||
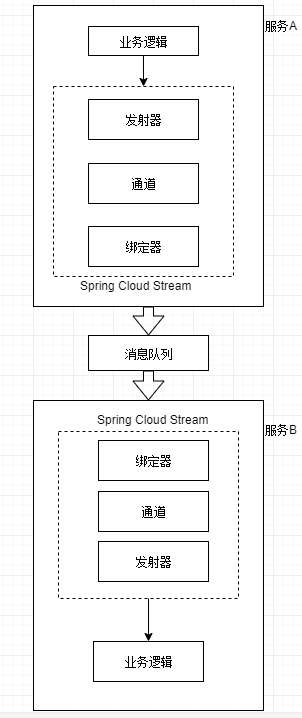
|
||||
|
||||
## 实战
|
||||
|
||||
  继续使用之前的项目,在许可证服务中缓存组织数据到 redis 中。
|
||||
|
||||
### 建立 redis 服务
|
||||
|
||||
  为方便起见,使用 docker 创建 redis,建立脚本如下:
|
||||
|
||||
```bash
|
||||
docker run -itd --name redis --net host redis:
|
||||
```
|
||||
|
||||
### 建立 kafka 服务
|
||||
|
||||
### 在组织服务中编写消息生产者
|
||||
|
||||
  首先在 organization 服务中引入 spring cloud stream 和 kafka 的依赖。
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-stream</artifactId>
|
||||
</dependency>
|
||||
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
  然后在 events 类中编写`SimpleSouce`类,用于组织数据修改,产生一条消息到队列中。代码如下:
|
||||
|
||||
```java
|
||||
@EnableBinding(Source.class)
|
||||
public class SimpleSource {
|
||||
private Logger logger = LoggerFactory.getLogger(SimpleSource.class);
|
||||
|
||||
private Source source;
|
||||
|
||||
@Autowired
|
||||
public SimpleSource(Source source) {
|
||||
this.source = source;
|
||||
}
|
||||
|
||||
public void publishOrChange(String action, String orgId) {
|
||||
logger.info("在请求:{}中,发送kafka消息:{} for Organization Id:{}", UserContextHolder.getContext().id, action, orgId);
|
||||
OrganizationChange change = new OrganizationChange(action, orgId, UserContextHolder.getContext().id);
|
||||
source.output().send(MessageBuilder.withPayload(change).build());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
这里使用的是默认通道,Source 类定义的 output 通道发消息。后面通过 Sink 定义的 input 通道收消息。
|
||||
|
||||
  然后在`OrganizationController`类中定义一个 delete 方法,并注入 SimpleSouce 类,代码如下:
|
||||
|
||||
```java
|
||||
@Autowired
|
||||
private SimpleSource simpleSource;
|
||||
|
||||
@DeleteMapping(value = "/organization/{orgId}")
|
||||
public void deleteOne(@PathVariable("orgId") String id) {
|
||||
logger.debug("删除了组织:{}", id);
|
||||
simpleSource.publishOrChange("delete", id);
|
||||
}
|
||||
```
|
||||
|
||||
  最后在配置文件中加入消息队列的配置:
|
||||
|
||||
```yml
|
||||
# 省略了其他配置
|
||||
spring:
|
||||
cloud:
|
||||
stream:
|
||||
bindings:
|
||||
output:
|
||||
destination: orgChangeTopic
|
||||
content-type: application/json
|
||||
kafka:
|
||||
binder:
|
||||
# 替换为部署kafka的ip和端口
|
||||
zk-nodes: 192.168.226.5:2181
|
||||
brokers: 192.168.226.5:9092
|
||||
```
|
||||
|
||||
  现在我们可以测试下访问[localhost:5555/apis/org/organization/12](localhost:5555/apis/org/organization/12),可以看到控制台打印消息生成的日志。
|
||||
|
||||
### 在许可证服务中编写消息消费者
|
||||
|
||||
  集成 redis 的方法,参看[]()。这里不作说明。
|
||||
|
||||
  首先引入依赖,依赖项同上面组织服务。
|
||||
|
||||
  然后在 event 包下创建`OrgChange`的类,代码如下:
|
||||
|
||||
```java
|
||||
@EnableBinding(Sink.class) //使用Sink接口中定义的通道来监听传入消息
|
||||
public class OrgChange {
|
||||
|
||||
private Logger logger = LoggerFactory.getLogger(OrgChange.class);
|
||||
|
||||
@StreamListener(Sink.INPUT)
|
||||
public void loggerSink(OrganizationChange change){
|
||||
logger.info("收到一个消息,组织id为:{},关联id为:{}",change.getOrgId(),change.getId());
|
||||
//删除失效缓存
|
||||
RedisUtils.del(RedisKeyUtils.getOrgCacheKey(change.getOrgId()));
|
||||
}
|
||||
}
|
||||
|
||||
//下面两个都在util包下
|
||||
//RedisKeyUtils.java代码如下
|
||||
public class RedisKeyUtils {
|
||||
|
||||
private static final String ORG_CACHE_PREFIX = "orgCache_";
|
||||
|
||||
public static String getOrgCacheKey(String orgId){
|
||||
return ORG_CACHE_PREFIX+orgId;
|
||||
}
|
||||
}
|
||||
|
||||
//RedisUtils.java代码如下
|
||||
@Component
|
||||
@SuppressWarnings("all")
|
||||
public class RedisUtils {
|
||||
|
||||
public static RedisTemplate redisTemplate;
|
||||
|
||||
@Autowired
|
||||
public void setRedisTemplate(RedisTemplate redisTemplate) {
|
||||
RedisUtils.redisTemplate = redisTemplate;
|
||||
}
|
||||
|
||||
public static boolean setObj(String key,Object value){
|
||||
return setObj(key,value,0);
|
||||
}
|
||||
|
||||
/**
|
||||
* Description:
|
||||
*
|
||||
* @author fanxb
|
||||
* @date 2019/2/21 15:21
|
||||
* @param key 键
|
||||
* @param value 值
|
||||
* @param time 过期时间,单位ms
|
||||
* @return boolean 是否成功
|
||||
*/
|
||||
public static boolean setObj(String key,Object value,long time){
|
||||
try{
|
||||
if(time<=0){
|
||||
redisTemplate.opsForValue().set(key,value);
|
||||
}else{
|
||||
redisTemplate.opsForValue().set(key,value,time,TimeUnit.MILLISECONDS);
|
||||
}
|
||||
return true;
|
||||
}catch (Exception e){
|
||||
e.printStackTrace();
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
public static Object get(String key){
|
||||
if(key==null){
|
||||
return null;
|
||||
}
|
||||
try{
|
||||
Object obj = redisTemplate.opsForValue().get(key);
|
||||
return obj;
|
||||
}catch (Exception e){
|
||||
e.printStackTrace();
|
||||
return null;
|
||||
}
|
||||
}
|
||||
|
||||
public static void del(String... key){
|
||||
if(key!=null && key.length>0){
|
||||
redisTemplate.delete(CollectionUtils.arrayToList(key));
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
  上面用到的是 Sink.INPUT 通道,这个和之前的 Source.OUTPUT 通道刚好一队,一个负责收,一个负责发。
|
||||
|
||||
  然后修改`OrganizationByRibbonService.java`文件中的`getOrganizationWithRibbon`方法:
|
||||
|
||||
```java
|
||||
public Organization getOrganizationWithRibbon(String id) {
|
||||
String key = RedisKeyUtils.getOrgCacheKey(id);
|
||||
//先从redis缓存取数据
|
||||
Object res = RedisUtils.get(key);
|
||||
if (res == null) {
|
||||
logger.info("当前数据无缓存:{}", id);
|
||||
try{
|
||||
|
||||
ResponseEntity<Organization> responseEntity = restTemplate.exchange("http://organizationservice/organization/{id}",
|
||||
HttpMethod.GET, null, Organization.class, id);
|
||||
res = responseEntity.getBody();
|
||||
RedisUtils.setObj(key, res);
|
||||
}catch (Exception e){
|
||||
e.printStackTrace();
|
||||
}
|
||||
} else {
|
||||
logger.info("当前数据为缓存数据:{}", id);
|
||||
}
|
||||
return (Organization) res;
|
||||
}
|
||||
```
|
||||
|
||||
  最后修改配置文件,为 input 通道指定 topic,配置如下:
|
||||
|
||||
```yaml
|
||||
spring:
|
||||
cloud:
|
||||
stream:
|
||||
bindings:
|
||||
input:
|
||||
destination: orgChangeTopic
|
||||
content-type: application/json
|
||||
# 定义将要消费消息的消费者组的名称
|
||||
# 可能多个服务监听同一个消息队列。如果定义了消费者组,那么同组中只要有一个消费了消息,剩余的不会再次消费该消息,保证只有消息的
|
||||
# 一个副本会被该组的某个实例所消费
|
||||
group: licensingGroup
|
||||
kafka:
|
||||
binder:
|
||||
zk-nodes: 192.168.226.5:2181
|
||||
brokers: 192.168.226.5:9092
|
||||
```
|
||||
|
||||
基本和发送的配置相同,只是这里是为`input`通道映射队列,然后还定义了一个组名,避免一个消息被重复消费。
|
||||
|
||||
  现在来多次访问[localhost:5555/apis/licensingservice/licensingByRibbon/12](localhost:5555/apis/licensingservice/licensingByRibbon/12),可以看到 licensingservice 控制台打印数据从缓存中读取,如下所示:
|
||||
|
||||

|
||||
|
||||
然后再以 delete 访问[localhost:5555/apis/org/organization/12](localhost:5555/apis/org/organization/12)清除缓存,再次访问 licensingservice 服务,结果如下:
|
||||
|
||||

|
||||
|
||||
### 自定义通道
|
||||
|
||||
  上面用的是`Spring Cloud Stream`自带的 input/output 通道,那么要如何自定义通道呢?下面以自定义`customInput/customOutput`通道为例。
|
||||
|
||||
#### 自定义发数据通道
|
||||
|
||||
```java
|
||||
public interface CustomOutput {
|
||||
@Output("customOutput")
|
||||
MessageChannel out();
|
||||
}
|
||||
```
|
||||
|
||||
  对于每个自定义的发数据通道,需使用@OutPut 注解标记的返回 MessageChannel 类的方法。
|
||||
|
||||
#### 自定义收数据通道
|
||||
|
||||
```java
|
||||
public interface CustomInput {
|
||||
|
||||
@Input("customInput")
|
||||
SubscribableChannel in();
|
||||
}
|
||||
```
|
||||
|
||||
  同上,对应自定义的收数据通道,需要使用@Input 注解标记的返回 SubscribableChannel 类的方法。
|
||||
|
||||
# 结束
|
||||
|
||||
  看完本篇你应该已经能够在 Spring Cloud 中集成 Spring Cloud Stream 消息队列了,貌似这个也能用到普通的 spring boot 项目中,比直接集成 mq 更加的优雅。
|
||||
|
||||
_2019,Fighting!_
|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](http://tapme.top/blog/detail/2019-01-03-19-19)
|
||||
|
||||
**本篇所用全部代码:**[FleyX 的 github](https://github.com/FleyX/demo-project/tree/master/springcloud/spring-cloud-stream%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97)
|
||||
@ -1,61 +0,0 @@
|
||||
---
|
||||
id: '2019-02-03-19-19'
|
||||
date: '2019/02/03 19:19'
|
||||
title: 'springCloud学习6(Spring Cloud Sleuth 分布式跟踪)'
|
||||
tags: ['spring-boot', 'spring-cloud', 'spring-cloud-sleuth']
|
||||
categories:
|
||||
- 'java'
|
||||
- 'springCloud实战'
|
||||
---
|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](http://tapme.top/blog/detail/2019-01-03-19-19)
|
||||
|
||||
# 前言
|
||||
|
||||
  在第四篇和第五篇中提到一个叫**关联id**的东西,用这个东西来将所有请求串起来,用来清晰的记录调用过程,以便以微服务的问题调试。
|
||||
|
||||
  微服务虽然能够将单体软件系统分解为更小的、更易于管理的小系统。但是这种特性是需要付出代价的。其中之一就是----调试困难。所以需要有一种办法能够将所有服务产生的消息聚合起来,方便的获取某一次用户请求的全部日志信息。本篇只解决将请求串起来这个问题,日志聚合需要对应的日志平台配合,这里不做讨论(其实就是将日志全部手机放到一个地方(比如es),再进行查询)。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
(PS:写这篇的时候突然发现,前面那种实现关联id方法是错误的,学习《spring微服务实战》过程中看到了不少错误,单大都不是很重要的,唯独关联id的那部分问题挺大。书上的实现是在每个服务中增加一个过滤器,提取入站请求中的关联id,然后存到ThreadLocal中,然后给服务调用类Ribbon加一个过滤器:用于从ThreadLocal中提取出关联id然后加入到请求的header中。这里的问题是前面的过滤器所在的线程和后面服务调用的线程不是同一个线程,也就无法用ThreadLocal来进行数据保存。在Feign请求的过程中是获取不到保存的值的)
|
||||
|
||||
# 集成Spring Cloud Sleuth
|
||||
|
||||
## 什么是Spring Cloud Sleuth
|
||||
|
||||
  简单来说Spring Cloud Sleuth就是为开发人员实现了前面关联ID尝试做的事情,而且做的更好。主要有一下几个功能:
|
||||
|
||||
- 透明地创建并注入一个关联ID到服务调用中(如果不存在关联ID)
|
||||
- 管理`关联ID`到出站服务的传播,将关联iD自动添加啊到出站调用中
|
||||
- 将`关联信息`添加到Spring的MDC日志记录,以便生成的`关联ID`由Spring Boot默认的SL4J和Logback实现自动记录
|
||||
|
||||
## 怎么用
|
||||
|
||||
  用法很简单,只需在要用的服务中引入`Spring Cloud Sleuth`依赖即可,代码如下:
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.cloud</groupId>
|
||||
<artifactId>spring-cloud-starter-sleuth</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
然后就会发现引入该依赖的服务日志打印语句中都会多一些数据,结构如下:
|
||||
```
|
||||
2019-02-28 11:03:02 [ERROR] [server Name,trace ID,span ID,isSendData]...
|
||||
```
|
||||
其中各项意义如下:
|
||||
- server Name:默认情况下使用`spring.applicataion.name`。
|
||||
- trace ID: 跟踪ID,相当于关联ID。整个微服务调用过程的唯一编号。
|
||||
- span ID: 跨度ID。表示某个服务过程中的唯一ID,比如在服务A中打印的日志跨度ID都是一样的。
|
||||
- isSendData: 是否发送数据给Zipkin。可配置是否将数据发给Zipkin,毕竟不是所有日志打印都是要收集的。
|
||||
|
||||
  使用过于简单,因此不提供代码,自己引入依赖就能看到效果,无需任何配置。
|
||||
|
||||
# 尾声
|
||||
|
||||
  微服务的分布式跟踪是一个很复杂的过程,上面所说的仅仅只是实现了给日志输入打上标记,让微服务调用能够串在一起。之后还有一个很重要的过程是日志收集和分析。后面如果有时间,可能会继续更新完成日志聚合。
|
||||
|
||||
_2019,Fighting!_
|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](http://tapme.top/blog/detail/2019-02-03-19-19)
|
||||
|
||||
@ -1 +0,0 @@
|
||||
<mxfile modified="2019-01-18T05:12:36.853Z" host="www.draw.io" agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/9.3.1 Chrome/66.0.3359.181 Electron/3.0.6 Safari/537.36" etag="N256S-eO6hUqJeOGiOxy" version="10.1.0" type="device"><diagram id="9zkqc596u_c2AOWQja2X" name="第 1 页">3VnbcqM4EP0aPc4UILDhEWy8qansbiqZqtnZNwwKaEZGLiHf8vUrCXG3Hc/Ejr3JQ0pqdQvRp093CwM4WWz/YNEy+5MmiADLSLYAToFledAQ/6VgVwpGjlUKUoaTUmQ2gif8grRQ26UrnKCio8gpJRwvu8KY5jmKeUcWMUY3XbVnSrpPXUYpGgie4ogMpd9wwrNSCqFhNAt3CKeZfrRY8sqVRVRpa9UiixK6aYlgCOCEUcrL0WI7QUQ6r3JMaTc7sFqfjKGcn2LwmD2O7v4yXtY//OWXEL083H3799NYn43vqjdGiXCAnlLGM5rSPCJhIw0YXeUJkrsaYpbxBRFDUwzFQdjuHy1Xk+9y8tmpptNte3G607MfiPOdxj5acSpEzZPvKV3q/cuzygMedIEWFXTFYnTkvatYiliK+BE9WAMlIhzRBRLnFnYMkYjjdfcckY61tNZr0BADDcgvgKP3XUdkpZ8EQhf4IQhcEDrAnQF/piQz4JogHAFvAtypWvKBb8qBUPYtueS6IBiDcAz8QOr3URfBuZTD1YL4MadMeHuNGMeCCffRHJEHWmCOaS5U5pRzuhAKRC4EUfwzVRExoUTaid3gs/pr7eETnEpbLrFshwxdcYJzNKnpa9Q4S1u0PY70EJnKoCKozjt1Qtm0WKxFWYu/I+NSWDoXYZp580yzTmSafU2mWXuYNgZBAFy7Gox/kWAjIt42mDMxSrly6VDywUk4tuwbI6Ex8PkbSHgFMsH/BZngwMsntAxN7vreXrudRHaq7y3rms6Hb+wZjiO3yTBHT8tIOWojOv4ummfIGZb9euE2rXdNGsNwPkuPfPMBb79Tj6xMfcaiXUthSXHOi9bOD1LQxInTjxOvd/vp6cN+Q9jVF4PyBE2c1K/y+6Fj/15bcW0O2u7NcfDAVWgmfSj9JhoxR3nSAYGh2rGpTHp9Twqf8K67GCrwSzRXCtK7Ou6EthMAZyokkm1FSTxpEOkuiqBnfrC5KgQ8OE+/KlqKMDgPLIbZg8UewDLag4p1MVT2xfdIVhqBR+gBzwN+GegT4EHVLU+B5340VPqJxbkuKtYwgbxDkxuv2FrZn/v6aJxYhQ6g9E4tr/HGtuvITbI095SOKBeBX2U+VToCE7jKyodApG1JNlvtc/jpr9Ov4Iz+RNVdMqe5DJFnTEhPVLEuFrAitod3C5wkKr72Fa1uzJ2Biv2PPnA8rFveHio6F6Pi8LvCI0pwMYCguvnHO3ERT5QrXynz89J59/NaUH8D+Lu8zp+xJx93/eoM3bovw7kXc+v+uqMZILg1U93Ax6470IAdUMyRdam6I6bNzxRlb9z82APD/wA=</diagram></mxfile>
|
||||
@ -1 +0,0 @@
|
||||
<mxfile modified="2019-02-13T09:27:02.046Z" host="www.draw.io" agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/9.3.1 Chrome/66.0.3359.181 Electron/3.0.6 Safari/537.36" etag="rO7Vb38IsYgF-0eN2kDW" version="10.2.2" type="device"><diagram id="pB5UQKRq5cwNq2AcJG5U" name="第 1 页">5Vpbk9MgGP01POqEkKTJY9JmdRwdL3XG1Tds2Caalg6htvXXCwlJGmDtutub+rILH7dwvsPHAQrQeLF9wfAqf0MzUgLXybYATYDrRl4g/krDrjEEUdgY5qzIGhPsDdPiJ1FGR1nXRUaqQUVOacmL1dA4o8slmfGBDTNGN8Nqd7QcjrrCc2IYpjNcmtZPRcbzxoqQ4/QFL0kxz9XQoihqSha4ra2qVjnO6GbPhFKAxoxS3qQW2zEpJXgtME27m3tKuy9jZMkf0mD3/evNq/QWf6neh5++fXhLg5fZs/bjfuByraYM0gAkAQhDmQghiG9AGgHht0gkfGmPRmpGfNfixOh6mRE5kgNQsskLTqYrPJOlG0EMYcv5ohQ5KJJqSMI42d47GdhBJLhF6IJwthNVVAPP95smilcoUBPZ9F6C7eTyPQch1Q4rYsy7rnvoREKh9ydIQhNJHSVBgZVM3pVkG0t2CjDIMlPJyazEVVXMhmCRbcFvJa7PfZX7vFcy2SrI68xOZZqBSWZwW4NXfBxdsxn5zbSUqzlmc8IPEsn0154/fIs7WhsjJebFj+H32nykRnhHCzGTjg5u635FB89zhl0081St9heJ1hGCw45QpHXUAGF0VFOmm/YTWOReD4sEV9hur5HMft4v65vVuROwr13BB+kXXZJ9I6SxDz6Sfb6rRbXRedk3Oky+swd6R1uQZpzvbIM47/zGjU8K9MGRQcpwldd1j4WYO0QMQmhujaEFMqjHuuPtjciASIaHqcpSxnM6p0tcpr01GYK4H8seGZe+Ec53SmLiNafC1I/8mtLVwAdHiV+tZD0UvgK7Rx8cl57kHYtwST2QCJ0X14IvBjGUElBwJklAGoIkBRE0PHppCehbaA4tNHejE+GILDgK+G4kWCKROCD0ZCKKQBxeHXzQ9R6Gny6tjoafZ8GvZp3kYSSPIpEZRy4OWxheGDbfAttIrtSGdnGq1vF10u7By/Zk+IUW/AIQjUE46cJfbOAmEOBDcBipip/4a11BYrmSKq3+WD8B/kRY5KZTNfuPbIDLYr4U6ZLcya4krMUMl7Eyc7khJZVwRrGcf6x3J7FEjuKEwBCshg9sctk9lQugKTynKyamLWzjkq4z8X/KGcGLf8sPnqfpfceyGGzq9mSeiMzFcPGIoZ0AvPaQdPAIoB/DjsdXy63ZlZ0BhsTy/MAklvUMEIxOhdnfKjO1q6UgsEB51g0LWu6IrlloBppOvzyANqV+fUpTxw1eHDebQr9iqakB2OUvB6BNq+taMzGA+6s1jqE1PdML5xWb5gXe/yE2A3foCGRZDmcVm64lnuiQ/6MPG23YOXgzCO9x6nleNpC2eLuXjj9+Vws1FRVqHT36ZUNk+zf0pnr/SwSU/gI=</diagram></mxfile>
|
||||
@ -1 +0,0 @@
|
||||
<mxfile modified="2018-12-03T03:34:21.048Z" host="www.draw.io" agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/9.3.1 Chrome/66.0.3359.181 Electron/3.0.6 Safari/537.36" etag="cRKRIEcnK_FnG5UI9HJy" version="9.5.2" type="device"><diagram id="hBJEmiHgUx6aHaSH3H_m" name="第 1 页">7Vptc9o4EP41+tgbvyN/tMG0nWk/3OV6vXx0sAK+GsQZkYT79bcryxhjYUwaYkg6k8lYq/fdfZ5dSRB7OH/6mMfL2VeesIxYRvJE7BGxLN/x4D8KNoXA851CMM3TpBCZleAm/Y8poaGk6zRhq1pDwXkm0mVdOOGLBZuImizOc/5Yb3bPs/qsy3jKGoKbSZw1pd/TRMwKqW0bRlXxiaXTmZoaqvyiZh6XrVXT1SxO+OOOyI6IPcw5F8XX/GnIMlReqZii3/hA7XZlOVuILh3+WkfD+08PXxM6/7b5/Vv2+ePt+MNArU1syh2zBBSgijwXMz7liziLKmmY8/UiYTiqAaWZmGfwacLnP0yIjbJhvBYcRNUIXzhfqnbFnDjRwa0o0Yqv8wlrWX/pE3E+ZaKlnb1VOHgq43Mm8g30y1kWi/Shvo5Y+cx0267SKnwoxZ6gZDXuQ5yt1Uzf2R2JXBJEJLBI5BFKSTgg0YAEIQnGDZs8sFyk4JRBlk4XIBKoyjBWpYzdw9bD1TKepIvpn1LNtBJ8kdUjq5L8ofzVlLJZvMRpJus7NO6qMJ+Jpk3SHDCVcpwELIH+HN7zhSjdw6mbX+0S1sqe2g3bNITqYFMFFkUXtio+VtgzS2qY7cDONc5kOvqS+AAl5Ju/Uf6bWxZvVbMesGNdA3asBnYQOGGE2AHg+ENCRyihAQnMhrHeDXBc98KAY2vtdojwIig6xC8+RvgHjf0RoQOUgGE1tn1ZBTpeXYGm07cGLb+VexZ8cU1k43QkG8vpk21K2DxX50+pKFRuuap42zTH4KrsYfRpD0fDIlSShynpxCbURDoJJElgYIB40MyfzksV26SlN6pwNWqC2Ah6GUlGHUiOBUb1UVN962t7IupNX542OPkGoZF0K0cGnr7dyuhbTWaTDY+HG7NGbjL29EBvfkd66zW39V88R4LG4Kq+LccZEZ/KNkOF+r1kGT/GxJe9wPFDQ7XBKXziD3A6BAGQrCFHduTCXLkwKfEDQp22fLxaPExhkbCZ0gBeRN2TViLnP9iQZzyvQu59mmV7ojKLn4BzMJCH+8n+PE0SeSB7nKWC3UAKj3M+5vGyEcNfAL6eu59Auk34ehr4Dtxzwdf+qWSmj9ucrkdSt0/Ylqt8drhFVJgSMA4Jx4hhLTgPEgH0orKxI9EeIFyBBYruGLyKZUA4syVKHbkMWYV5k+SRwN0B8NFz9JtBqeV2yEVcDUq9swVZ9+pQ2vXs4PWKUv3Z4TgqPBn6PBKNJVyHnVLDKk56GD/VOLQkAoMEXgkzXwXeQPaCYlAGcJxrF5MhsgOCPMTBC4qBEIpzmUgKbxal+7FUmwq/LkrbH0q6X8ZcRHZseh0R3OtljKk7pnU4/WPyGiC+MWJ6iJ7nhNdgJ84WBDBsi5gaatnyR4FgVxf3i8Sd7qTgu8Edsny7ddJmJkCRhIDAUBuGPCRIjqHGDv3AUl01YBjg1t4skeyHe+1VzasSiaVJHvfVPwU9LA/uXj11x3dlc+NkrZRHDqUVR6eVgUYr2+uHl1eLoVGLl6EX3uXwNRXSIX5GkqQPNTV7/67x6T1EZ/+g/DaAFvJVaFu7PwrsTg5USlvvR3Q+fuqlUYsXNQ18zID+2eIj1XC15Fi/oLuI0PBNv8+dZKdymL3DSBOGuguD8933HbyQ2jFik67evREvy4rlvro9mQfXHPyfYy63Hvv8btayzmYtzUP5a+cDrlP34EvIBzSn91/5wBEvuqB8wNI9Sf7KBw7Z6TLzAUv/Tvru84FjRrwwKw5OyQeaFHb1+UC7uV4tH4Bi9WNvWbfzk3k7+h8=</diagram></mxfile>
|
||||
@ -1 +0,0 @@
|
||||
<mxfile userAgent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/9.3.1 Chrome/66.0.3359.181 Electron/3.0.6 Safari/537.36" version="9.4.6" editor="www.draw.io" type="device"><diagram name="Page-1" id="5f0bae14-7c28-e335-631c-24af17079c00">7R3bkqO28mt4jAtZgKRH8CVJVVK1lT1V5+SRtRmbxGOmbCYzk68/kpAMSMJgWxjbM1tbuyAJXbpbre5Wd9uBk+f3n3fxy/r3bJlsnLG7fHfg1BmPgecD+h8r+ShKEMBFwWqXLkWjsuB7+m8iCl1R+pouk32tYZ5lmzx9qRcusu02WeS1sni3y97qzZ6yTX3Ul3iVaAXfF/FGL/1vuszXRSmErltW/JKkq7UYmlaRouZHvPh7tctet2JAZwyf+J+i+jmWnYme9ut4mb1ViuDMgZNdluXF0/P7JNkw4Eq4Fd/NG2oPE98l27zTB6j44p9485rIKfOJ5R8SGmw9L6JZssuTdxMO4h+yuavPARxWRkkmyZ6TfPdBm4iOfJeM/OKjD0lBopO3EvpjKMrWVcDL0WKB8dWh93LR9EGs2wwDfBUQoKMwkJ8cAQAgBgBgC+sPrrF+bF5+2/p8C+vz9PXNAodMHDx1Zr6DQycErCQKHIydGXYiz4kIe6DQxZKXVaDBQJBSbhFu0tWWFuXZiwOjWLxtkic6+Wj/Ei/S7eo/rG6Ky4LfePV0XJb8IZYLeNk6fmHDLF5/JOy14I2UMcJome4olNOMDbLPXhncoqdsm38XM/Po+zp/3rD29LERXVW0BK1owT1hxb8MKzqNPj5W5AdAZw59YQn4GpyTJT0rxWu2y9fZKtvGm1lZGvHzL2E9uPXF/5Xk+Yc47uPXPKNFZQ+/ZRwpJZDYQI0gkgcXBfluIZvBoiyPd6skr2x+HZS7ZBPn6T/1/i8CVHDngPKvBSh45sZHThg54ZxXuU5UVM3ZhzOPvbLP6cPEISFrTCL2IW2MZ07o85I5fyAOBg6BvIp+7vKvZqy9YRqI9Ya9X7+xMlpJR2YPU8aEZnM2Gp6wknDmYN4lwXyOtMuIjWzo0ufD8r5pg8gVjUPIR6O8LeBzHPMS+oD4EJg3RvLz4NTJqsRJ2U9ep7l9vsv+TibZJtvRkm22ZRT6lG42SpHkqAtKYgktj1TG+5wul5y839Zpnnyn7JSN+UZVBY3kO3HDJtGpTThENmQHcBXh8Ci/h9BT5GNvrJ8AvukIAIEFGMCrCMheAxCus8QOalCdck20feoxD9uF4v6WbFJ7OnErzKooe2IlY8qZH1o+bkKR+ILU1TaT1uYaEGgFf8QS/h5akm7B30FGHgCB8si6GIHwEyPQGw+IQIMkq+kA22XIDJIMYJt4v08XdRgk72n+P3akjKgAXrz+Kau2dD7VOvb+pzh+lvF+zc+ijlqAPMOrWoDkIFUtoIOdxj+ianbWFsQI37KUzrDUbIM6NseugqZi+uKrccWsqXR0sCRLe5qqCxdr1jriKD8suxsVGMxL51MBqlKBW6cCVKMCYIsKsIEKyJBUMFaoIPDPJAL3eD8WacBgzLorGjBwAug6A9KAp2xgciYjgP7xfizSQAcz+i2fBlIcuR0+4IG61que2d1p4Hg/FmngXJncdyLAhDmVYO7IStMkqMkT2CCYSbZZu9GzcbVgkKxVyPZutFEE0wD7GgACk2QKrJitOphs7Nsz/PYjo8clm+zK3DBLZsLEi6OHtlU0gf/dqe2Kj/prBTm9XcCabmBV1Dy0GaIFNQD7g+HGdA+r4uahLQwtuIFguH1jECk13HifGDfegDzNcGOgiXqhhps7EuhaYH+4XpMCHtSB7xmAb0PA87rK2fWt8sDYAEh1odOxEfQlbo91bJys+VbUW+LVbBwj10Wy4FuyS+n8GMQLy8hBYYZuzWoycn0i3tVvnHb9WIqJFfXYM5jJYPvFdI/qse+iGsYDBOtddNWPfYnAg37cm4Ls2zCZl6TiI3QGqfgIqwa2ByaTACnYPdeM4lMeM8Y+Al7xr1c/egkYyRr2r0KLFklI90hrdKM616ba1f3qVLvbhQRj3RfLt2CzlBLh0yZ5Fw07g2Iw1qnsCahKhJ33hNKR1yPr7OCi8oi4CgIVV+A8XKkdeS7oDVdER03FGVTIkM1sq+RNbgCqzIkeXk3nm02XUZ1N+YOyKd2aOR4JM/rB2VK4drrc/ZN7hmIkSmgtK5lxm7vPfSyn3J8Ule6X5/tqBtKxNHAwYaM0e2byz6didPpA1ZM7VkmOG8CBYjfxDMr5wfBb5RueBZVEyjgVigEj6SfsiocwNKGqaMNdiKOQkRFrg5g3cunvWzgek7Z+CldkTnAENLRRiEknuMCJoBNiXhXUvY0f1d/3KF3hOlkhT79X6Y+s7Gq6boDqzB2Vqm+T+iLF2vI0OI+hyx1Si5UY1PnngCGBWXyuoqJ6ZWLQm1AW6NbXMw964uM6LQQYX3rUH9QfWzRjCBu5mhAQ6KYDODrPYZKJBYyle7wxv3tnrDhkASZdzIjlce6zWBJ29vv8sEC8zVwEsLCq+eMyYqI6P5sO+L7i0oLj4VYnbbybELClcbYLP7a/t/RLQK9hb6lb4Yh000V4PrThgjrmXzHRHXIhCzHZh7WZsG06g7xNcQcW8IeATYZFgJkCyMIpl/yLnQ0q4tspHjnsoZhqoS9EnHkQJ6S7f8zVjYlprKJqWmEV6qBUavs0rMEopPXGGm4gpQHAiu8aQRoA+ktoEFwlYCu44YwGhvvBHgBw3OPtJ9htwTZoXio8XzkOTNH07V6sffEiZAgf/cpy0IKXAdIcIB3QtxG9Hxii95FQOquiImpwD7AuKiLdF+zOINVwctuHlO71CLjVOpqK9AOd2QCXOSfccom56At4G1daAT1uIDR1qFouub6LeeOQi9NV8zX9PJxUbImImzC5BE7lW4KPSLO6asCsklJgv2NBt0nKkRFqumBrlOt8aIGgOkQZ9S7YBt6wyQjQVbJVoYZsKNdZ4iDJCFB7Kqgel/yVjOACFA2fjAB9JSO4HH9DJiPA3RTIT56MoAWBQyYjwB0SFd1K+Kk8w2uiuiEEGX0lIzjxPlLK2vcQiG6kAoObEfpKRnAaDVhNSzIADRg4AW6PLP1KRlClAatJSa5/Gkhx5Hb4wP0lI8DdMuw+ZDKCJkFtgGQE+CoGizarDVROn6tmI8CDGDRwu0GjxyWbDBqfKhtBE/gHz0aATbaKT5WNoAU1A2YjkP1+3mwELbgZMBsBMVgYPlc2ghbcDJiNQNpNHzcbQQvsh8xGQLpltH+kbARtJ8iA2QiIDdV38GwENWVYiM81ZRjpSBk0TBNgYCkdAcBKoGaP+QiIjcSdg+YjuD9CIVhB77mmFIDHN5GRgOixCDedkcAiydj/dRi3myfAkZ+H0b2WipDOmWhM5vxhyv6KcEnE/aoA+9u/XaLNc1z7tQ9ocLAxeWJACz5GwO12k/+48Ce+Bn+gO+/3Bn9g0IBPPZHuMc0DwEpgL1TNcN2PBaUnr7/4TwAsXLvfJboIgeo2ORthel+9osyAoYoHc7L5kb1ZdV4uD/baVdkFgbgS0rUr0ksDcRu9IBQ3CKrcYeIhGGCPHhe+/PnQFkxRwo4/Ks1eWIP9kXF99eJdkESJ+aLL8+lAt1V1ysiixIseidnvN2IUmH7F72Iq6H5Q6VaPIimLHprZKCpwT/MQN8oM9LnMqsL91iO3SxYP5nt+cHk//JYeHxxjYYkJ+RwxjzKtzkhEe/JELdG84l5/SLtRcaYnLltuMTWWD6RLz5j//qDHFw151GiXS9lK7pH2HwJsjFh/5KBTqv/VOQZCutwMTM75QDUwnLchLIWkGxI+9c1IDLHnQhG4CifRjTBwdHQv6eyioHjJCsjctIFPCvsuUvxEQjERoTPFNAK26yL3cXeS5vp4+OH76k6yZE6nr+XP3RfnOF3W+vdsmbAW/wc=</diagram></mxfile>
|
||||
@ -1 +0,0 @@
|
||||
<mxfile userAgent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/9.3.1 Chrome/66.0.3359.181 Electron/3.0.6 Safari/537.36" version="9.4.4" editor="www.draw.io" type="device"><diagram name="Page-1" id="5f0bae14-7c28-e335-631c-24af17079c00">3ZlNc5s8EIB/jY7t8P1xBBu3h3SmMzn0fY+ykW1ajBghx3F/fVdiscHglMQumUkOGWm1+mD3YXeFiT3bPX8RtNx+4ynLiWWkz8SeE8sKHQ/+K8GxFnheUAs2IktrkXkWPGa/GQoNlO6zlFUdRcl5LrOyK1zxomAr2ZFRIfihq7bmeXfXkm5YT/C4onlf+iNL5RalpmGcB76ybLPFrQMXB5Z09Wsj+L7A/Yhlr/VfPbyjzVqoX21pyg8tkZ0QeyY4l3Vr9zxjuTJtY7Z63uLK6OncghVyzAR0SyWPzaPrwzM1bBA73spdDk0TmrCiOP6Hct35X3U+29D9yaQ8ohvpXnIQcSG3fMMLmj9wXuIa9W4s7Vn/fF4UVXwvVqhlIQFUbBhqOSdbAYKM7xgcB1QEy6nMnrqrU4Rhc9I7GwQaaJNh++DWTzTf46IkcUmckCghiUfCGQnmShJEJDJVA+QhDDlKJ4h71gV/l6q54ruSF/qhY5pnmwJkOVurblXSVVZsHnRvbnsnsz0xIdnzy4brm6SZ4CFx+EaaDvYPLb4bKrcttJt5t1gx7NlBIfCI3QIMAQ95FbyxcF0D1H8zePb9wcOp33kG+56841hd7/SsXh8BZ10Y/nSMUb6wPyrRlj0h0abZM8RrkH6/WOr2kfYmiqXuRyXPNqckz+ib8dIyqgIprz4oFk102agbrzWAY18kk8AdZwDTvYMFnAGOQgJHUPj4JJ5roHz1X3Hkk9AggTeA2JRAGcMGnYIY7wPZC4ELp3zh7JtC/b8N56Z1Y/AerkdcZ7J6xHo5k7J8yQ/JWTAmp352O1n1NSWk2g3ais4MroM3+qWbZ+/iqkgIemwplMoF1XhPNlfYxTX9i0rUNy78Wx/gzd4eulD1gxF0FyQMdAyKSezoBox6WtkgYaTj1IJE7qjSIQlIAAEuUg1QCGZaOSCxr6d7JDZ6FEJ4kl3CBKuy35g2FVVoe9B2Y+LOW9FvBWwwAYIGpAgHdlmaaoxzumR5fPpaMOM5F3rf5nvBC4FyTAL/Swb/BC8JWKTt6QC/Bbw1dOAyn+zuDL5eV+zWIGGOw2aQhLkGCSQWiXQjjkjYj+nvVk36xjveY6w+92+7x3Rj7gSJz+kH2JuT4eiSYKgE9VTECRxNWKwgU4DamjkNaGy1iiwYMocobNn2Dmh55sVFxeujZRsDaN2jTDdv++rzjmgN3JHNqT44mlduyTOV9jAvmjqxRZoxV3XD/mfcJpztd3m0krydix5U6vnOq0xmXEW3JZeS78blpMt8JpWt4/tS6ztuh1onGKL2H8XD4c9j15JI7ZBooR0S62oEyhIHddQ9ytEvvY9ZCcsS6Caq5EgW2rEzFTxgkVAHj8hTu9RlCaToemVV+bSUQ1dP99Sydb2E5znphPoYdSllKOHgrIvn+nsJVEnBf7GGDHyH11meX4jGF0KHbSbZI2RWtedB0LIXFO6AVGB1kToFuHaO9QeYsl7PFHTPv9/Utc75NzI7+QM=</diagram></mxfile>
|
||||
@ -1,214 +0,0 @@
|
||||
---
|
||||
id: "2018-09-22-15-57"
|
||||
date: "2018/09/22 15:57"
|
||||
title: "java导出EXCEL文件"
|
||||
tags: ["reflex", "java","excel","SXSSFWorksheet"]
|
||||
categories:
|
||||
- "java"
|
||||
- "java工具集"
|
||||
---
|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](tapme.top/blog/detail/2018-09-22-15-57)
|
||||
|
||||
**本篇所用到代码**:[github](https://github.com/FleyX/demo-project/blob/master/%E6%9D%82%E9%A1%B9/excel%E5%AF%BC%E5%87%BA.java)
|
||||
|
||||
**更新说明:**之前用的`HSSFWorkbook`有爆内存的风险,当数据量有几百万时该对象会占用大量内存。更换为`SXSSFWorkbook`可解决内存占用。
|
||||
|
||||
## 一、背景
|
||||
|
||||
  最近在 java 上做了一个 EXCEL 的导出功能,写了一个通用类,在这里分享分享,该类支持多 sheet,且无需手动进行复杂的类型转换,只需提供三个参数即可:
|
||||
|
||||
- `fileName`
|
||||
|
||||
excel 文件名
|
||||
|
||||
- `HasMap<String,List<?>> data`
|
||||
|
||||
具体的数据,每个 List 代表一张表的数据,?表示可为任意的自定义对象
|
||||
|
||||
- `LinkedHashMap<String,String[][]> headers`
|
||||
|
||||
`Stirng`代表 sheet 名。每个`String[][]`代表一个 sheet 的定义,举个例子如下:
|
||||
|
||||
```java
|
||||
String[][] header = {
|
||||
{"field1","参数1"}
|
||||
,{"field2","参数2"}
|
||||
,{"field3","参数3"}
|
||||
}
|
||||
```
|
||||
|
||||
其中的 field1,field2,field3 为对象中的属性名,参数 1,参数 2,参数 3 为列名,实际上这个指定了列的名称和这个列用到数据对象的哪个属性。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
## 二、怎么用
|
||||
|
||||
  以一个例子来说明怎么用,假设有两个类 A 和 B 定义如下:
|
||||
|
||||
```java
|
||||
public class A{
|
||||
private String name;
|
||||
private String address;
|
||||
}
|
||||
public class B{
|
||||
private int id;
|
||||
private double sum;
|
||||
private String cat;
|
||||
}
|
||||
```
|
||||
|
||||
现在我们通过查询数据库获得了 A 和 B 的两个列表:
|
||||
|
||||
```java
|
||||
List<A> dataA = .....;
|
||||
List<B> dataB = .....;
|
||||
```
|
||||
|
||||
我们将这两个导出到 excel 中,首先需要定义 sheet:
|
||||
|
||||
```java
|
||||
String[][] sheetA = {
|
||||
{"name","姓名"}
|
||||
,{"address","住址"}
|
||||
}
|
||||
String[][] sheetB = {
|
||||
{"id","ID"}
|
||||
,{"sum","余额"}
|
||||
,{"cat","猫的名字"}
|
||||
}
|
||||
```
|
||||
|
||||
然后将数据汇总构造一个 ExcelUtil:
|
||||
|
||||
```java
|
||||
String fileName = "测试Excel";
|
||||
HashMap<String,List<?>> data = new HashMap<>();
|
||||
//ASheet为表名,后面headers里的key要跟这里一致
|
||||
data.put("ASheet",dataA);
|
||||
data.put("BSheet",dataB);
|
||||
LinkedHashMap<String,String[][]> headers = new LinkedHashMap<>();
|
||||
headers.put("ASheet",sheetA);
|
||||
headers.put("BSheet",sheetB);
|
||||
ExcelUtil excelUtil = new ExcelUtil(fileName,data,headers);
|
||||
//获取表格对象
|
||||
SXSSFWorkbook workbook = excelUtil.createExcel();
|
||||
//这里内置了一个写到response的方法(判断浏览器类型设置合适的参数),如果想写到文件也是类似的
|
||||
workbook.writeToResponse(workbook,request,response);
|
||||
```
|
||||
|
||||
当然通常数据是通过数据库查询的,这里为了演示方便没有从数据库查找。
|
||||
|
||||
## 三、实现原理
|
||||
|
||||
  这里简单说明下实现过程,从调用`createExcel()`这里开始
|
||||
|
||||
#### 1、遍历 headers 创建 sheet
|
||||
|
||||
```java
|
||||
public SXSSFWorkbook createExcel() throws Exception {
|
||||
try {
|
||||
//只在内存中保留五百条记录,五百条之前的会写到磁盘上,后面无法再操作
|
||||
SXSSFWorkbook workbook = new SXSSFWorkbook(500);
|
||||
//遍历headers创建表格
|
||||
for (String key : headers.keySet()) {
|
||||
this.createSheet(workbook, key, headers.get(key), this.data.get(key));
|
||||
}
|
||||
return workbook;
|
||||
} catch (Exception e) {
|
||||
log.error("创建表格失败:{}", e.getMessage());
|
||||
throw e;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
将 workbook,sheet 名,表头数据,行数据传入 crateSheet 方法中创建 sheet。
|
||||
|
||||
#### 2、创建表头
|
||||
|
||||
  表头也就是一个表格的第一行,通常用来对列进行说明
|
||||
|
||||
```java
|
||||
private void createSheet(SXSSFWorkbook workbook, String sheetName, String[][] header, List<?> data) throws Exception {
|
||||
Sheet sheet = workbook.createSheet(sheetName);
|
||||
// 单元行,单元格
|
||||
Row row;
|
||||
Cell cell;
|
||||
//列数
|
||||
int cellNum = header.length;
|
||||
//设置表头
|
||||
row = sheet.createRow(0);
|
||||
for (int i = 0; i < cellNum; i++) {
|
||||
cell = row.createCell(i);
|
||||
String str = header[i][1];
|
||||
cell.setCellValue(str);
|
||||
//设置列宽为表头的宽度+4
|
||||
sheet.setColumnWidth(i, (str.getBytes("utf-8").length + 6) * 256);
|
||||
}
|
||||
|
||||
int rowNum = data.size();
|
||||
if (rowNum == 0) {
|
||||
return;
|
||||
}
|
||||
//获取Object 属性名与field属性的映射,后面通过反射获取值来设置到cell
|
||||
Field[] fields = data.get(0).getClass().getDeclaredFields();
|
||||
Map<String, Field> fieldMap = new HashMap<>(fields.length);
|
||||
for (Field field : fields) {
|
||||
field.setAccessible(true);
|
||||
fieldMap.put(field.getName(), field);
|
||||
}
|
||||
Object object;
|
||||
for (int i = 0; i < rowNum; i++) {
|
||||
row = sheet.createRow(i + 1);
|
||||
object = data.get(i);
|
||||
for (int j = 0; j < cellNum; j++) {
|
||||
cell = row.createCell(j);
|
||||
this.setCell(cell, object, fieldMap, header[j][0]);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 3、插入行数据
|
||||
|
||||
  这里是最重要的部分,首先通过数据的类对象获取它的反射属性 Field 类,然后将属性名和 Field 做一个 hash 映射,避免循环查找,提高插入速度,接着通过一个 switch 语句,根据属性类别设值,主要代码如下:
|
||||
|
||||
```java
|
||||
private void setCell(Cell cell, Object obj, Map<String, Field> fieldMap, String fieldName) throws Exception {
|
||||
Field field = fieldMap.get(fieldName);
|
||||
if(field == null){
|
||||
throw new Exception("找不到 "+fieldName+" 数据项");
|
||||
}
|
||||
Object value = field.get(obj);
|
||||
if (value == null) {
|
||||
cell.setCellValue("");
|
||||
} else {
|
||||
switch (field.getGenericType().getTypeName()) {
|
||||
case "java.lang.String":
|
||||
cell.setCellValue((String) value);
|
||||
break;
|
||||
case "java.lang.Integer":
|
||||
case "int":
|
||||
cell.setCellValue((int) value);
|
||||
break;
|
||||
case "java.lang.Double":
|
||||
case "double":
|
||||
cell.setCellValue((double) value);
|
||||
break;
|
||||
case "java.util.Date":
|
||||
cell.setCellValue(this.dateFormat.format((Date) value));
|
||||
break;
|
||||
default:
|
||||
cell.setCellValue(obj.toString());
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
完整代码可以到 github 上查看下载,这里就不列出来了。
|
||||
|
||||
github 地址:
|
||||
|
||||
**本篇所用到代码**:[github](https://github.com/FleyX/demo-project/blob/master/%E6%9D%82%E9%A1%B9/excel%E5%AF%BC%E5%87%BA.java)
|
||||
|
||||
**本篇原创发布于:**[FleyX 的个人博客](tapme.top/blog/detail/2018-09-22-15-57)
|
||||
@ -1,53 +0,0 @@
|
||||
---
|
||||
id: "2018-11-20-10-38-05"
|
||||
date: "2018/11/20 10:38:05"
|
||||
title: "1.linux下mongodb的配置与安装"
|
||||
tags: ["docker", "linux","ubuntu"]
|
||||
categories:
|
||||
- "linux"
|
||||
- "docker教程"
|
||||
---
|
||||
|
||||
# 一、安装
|
||||
|
||||
  有两种安装方法,脚本安装和apt安装
|
||||
|
||||
## 1、脚本安装
|
||||
|
||||
  root下执行以下命令(非root下会要求输入密码):
|
||||
```bash
|
||||
wget -qO- https://get.docker.com/ | sh
|
||||
```
|
||||
等待执行完毕后会有如下提示:
|
||||
```
|
||||
If you would like to use Docker as a non-root user, you should now consider
|
||||
adding your user to the "docker" group with something like:
|
||||
|
||||
sudo usermod -aG docker 用户名
|
||||
Remember that you will have to log out and back in for this to take effect!
|
||||
```
|
||||
就是如果要以非root用户直接运行docker时需要执行`sudo usermod -aG docker 非root用户名`,然后重新登陆即可。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
## 2、apt安装
|
||||
  直接运行(root下)
|
||||
```bash
|
||||
apt-get update
|
||||
apt-get install docker.io
|
||||
```
|
||||
|
||||
# 二、配置国内源
|
||||
|
||||
  国外源太慢配置为国内源。修改或创建`/etc/docker/daemon.json`,内容如下:
|
||||
```json
|
||||
{
|
||||
"registry-mirrors": [
|
||||
"加速地址"
|
||||
],
|
||||
"insecure-registries": []
|
||||
}
|
||||
```
|
||||
以下是国内加速地址:
|
||||
- 网易 [http://hub-mirror.c.163.com](http://hub-mirror.c.163.com)
|
||||
- ustc [https://docker.mirrors.ustc.edu.cn](https://docker.mirrors.ustc.edu.cn)
|
||||
@ -1,135 +0,0 @@
|
||||
---
|
||||
id: "2018-12-26-13-18"
|
||||
date: "2018/12/26 13:18"
|
||||
title: "2.docker简单使用教程"
|
||||
tags: ["docker","mysql"]
|
||||
categories:
|
||||
- "linux"
|
||||
- "docker教程"
|
||||
---
|
||||
|
||||
### 1、镜像操作
|
||||
|
||||
#### 1. 列出镜像
|
||||
|
||||
```bash
|
||||
docker images;
|
||||
```
|
||||
|
||||
#### 2. 删除镜像
|
||||
|
||||
```bash
|
||||
docker rmi 镜像id/镜像名:版本
|
||||
```
|
||||
|
||||
#### 3. 搜索镜像
|
||||
|
||||
```bash
|
||||
docker search 镜像名
|
||||
```
|
||||
|
||||
<!-- more -->
|
||||
|
||||
#### 4. 拉取镜像
|
||||
|
||||
```bash
|
||||
#如不加tag默认拉取latest
|
||||
docker pull name:tag
|
||||
```
|
||||
|
||||
#### 5. 镜像导出/导入文件
|
||||
|
||||
```bash
|
||||
# 使用name:tag或者id确定要导出的镜像,> 导出的路径
|
||||
docker save name:tag/id > /home/image-save.tar
|
||||
|
||||
# 加载镜像文件到docker中
|
||||
docker load -i /home/image-save.tar
|
||||
```
|
||||
|
||||
#### 6. 查看镜像创建历史
|
||||
|
||||
```bash
|
||||
docker history [options] image
|
||||
# -H:已可读的格式打印镜像大小和日期,默认使用
|
||||
# --no-trunc:显示完整的提交记录
|
||||
# -q:仅列出提交记录id
|
||||
```
|
||||
|
||||
#### 7. 容器保存为镜像
|
||||
|
||||
```bash
|
||||
docker commit -m "提交信息" -a "作者信息" 容器id/容器名 镜像名:镜像tag
|
||||
```
|
||||
|
||||
### 2.容器操作
|
||||
|
||||
#### 1.通过镜像创建容器
|
||||
|
||||
```bash
|
||||
docker run -itd -p 3306:3306 -p 9200:9200 -w /home --name oms_env oms_env:0.6
|
||||
|
||||
# 参数说明
|
||||
-i #让容器的标准输入 通常it配合使用
|
||||
-t #docker分配一个伪终端并绑定到容器的标准输入上
|
||||
-d #容器后台运行
|
||||
-p 8080:80 #小写p,hostPort:ContainerPort 绑定容器端口到当前主机端口
|
||||
-P #大写P,docker随机映射一个端口到容器内部开放的网络端口
|
||||
-w #指定容器工作空间
|
||||
--bind 容器名[:容器别名] #容器链接
|
||||
```
|
||||
|
||||
#### 2.保存容器到文件/恢复文件到镜像
|
||||
|
||||
```bash
|
||||
# 保存容器到文件
|
||||
docker export 容器名/容器id > /home/container_export.tar
|
||||
|
||||
#从文件恢复镜像
|
||||
docker import - test:v1 < /home/container_export.tar
|
||||
```
|
||||
|
||||
#### 3.删除容器
|
||||
|
||||
```bash
|
||||
docker rm 容器id/容器名
|
||||
```
|
||||
|
||||
#### 4.拷贝文件到容器内
|
||||
|
||||
```bash
|
||||
docker cp hostPath 容器id:containerPath
|
||||
#例如
|
||||
docker cp /home/ubuntu ecc:/home
|
||||
#将本机的/home/ubuntu目录拷贝到了以ecc开头的容器内的home目录
|
||||
```
|
||||
|
||||
#### 5.从容器拷贝文件到主机
|
||||
|
||||
```bash
|
||||
docker cp 容器id:containerPath hostPath
|
||||
#例如
|
||||
docker cp ecc:/home/ubuntu /home
|
||||
#将ecc开头的容器内的ubuntu目录拷贝到了本机的/home目录
|
||||
```
|
||||
|
||||
#### 6.连接到容器
|
||||
|
||||
  有三种办法
|
||||
|
||||
1. 通过 attach 直接进入到容器,用法如下:
|
||||
|
||||
```bash
|
||||
docker attach containerName/containerId
|
||||
```
|
||||
|
||||
不推荐此种用法,同时只能有一个终端操作容器,即时有多个终端连入,界面会同步变化
|
||||
|
||||
2. 通过exec连接容器,用法如下:
|
||||
```bash
|
||||
docker exec -it containerName/containerId bash
|
||||
```
|
||||
|
||||
以bash连入容器,推荐此种用法,支持多终端连入操作。
|
||||
|
||||
3.通过给容器安装ssh服务,支持多终端连入,不推荐,太麻烦了。
|
||||
@ -1,49 +0,0 @@
|
||||
---
|
||||
id: "2018-11-20-10-38-05"
|
||||
date: "2018/11/20 10:38:05"
|
||||
title: "linux下mongodb的配置与安装"
|
||||
tags: ["mongodb", "linux"]
|
||||
categories:
|
||||
- "linux"
|
||||
- "软件相关"
|
||||
---
|
||||
|
||||
  首先到官网下载安装包,官网地址如下:[点击跳转](https://www.mongodb.com/download-center/community),选中合适的版本,下面会出现下载链接,然后使用 wget url 下载到当前文件夹下。mongodb 4.04 ubuntu18.04 64 下载命令如下:
|
||||
|
||||
```shell
|
||||
wget https://fastdl.mongodb.org/win32/mongodb-win32-x86_64-2008plus-ssl-4.0.4.zip
|
||||
|
||||
```
|
||||
|
||||
  然后解压文件到当前文件夹
|
||||
|
||||
```shell
|
||||
tar -zxvf mongodb-linux-x86_64-ubuntu1804-4.0.4.tgz
|
||||
|
||||
```
|
||||
|
||||
  然后编写配置文件,进入到解压后的目录下,创建文件 mongodb.conf,填入如下内容:
|
||||
|
||||
```properties
|
||||
dbpath = /usr/local/mongodb/data/db #数据文件存放目录
|
||||
|
||||
logpath = /usr/local/mongodb/logs/mongodb.log #日志文件,注意这是文件路径,不是文件夹路径
|
||||
|
||||
port = 27017 #端口
|
||||
|
||||
fork = true #以守护程序的方式启用,即在后台运行
|
||||
|
||||
auth = true #开启认证
|
||||
|
||||
```
|
||||
|
||||
  然后就可以启动
|
||||
|
||||
<!-- more -->
|
||||
|
||||
```shell
|
||||
./bin/mongod -f mongodb.conf
|
||||
|
||||
```
|
||||
|
||||
ps:关于身份认证,可以先将auth设置成false,然后连接mongodb创建用户,创建用户完了后再将auth改成true。
|
||||
@ -1,511 +0,0 @@
|
||||
---
|
||||
id: "2018-10-01-13-58"
|
||||
date: "2018/10/01 13:58"
|
||||
title: "node,vue开发教学管理系统"
|
||||
tags: ["node", "vue","element-ui","axios","koa","redis","mysql","jwt"]
|
||||
categories:
|
||||
- "node"
|
||||
- "项目"
|
||||
---
|
||||
|
||||
  毕业才刚刚两个多月而已,现在想想大学生活是已经是那么的遥不可及,感觉已经过了好久好久,社会了两个月才明白学校的好啊。。。额,扯远了,自从毕业开始就想找个时间写下毕设的记录总结,结果找了好久好久到今天才开始动笔。
|
||||
|
||||
  我的毕业设计题目是:教学辅助系统的设计与实现,,是不是很俗。。。至于为啥是这个题目呢,完全是被导师坑了。。。。。
|
||||
|
||||
## 1、需求分析
|
||||
|
||||
  拿到这个题目想着这个可能被做了无数次了,就像着哪里能够做出点创新,,最后强行创新出了一个个性化组题(根据学生水平出题)和徽章激励(达到某个要求给予一个徽章)。最后就产生了如下需求,系统有学生端和管理端:
|
||||
|
||||
学生端:
|
||||
|
||||
- 个人资料设置
|
||||
- 徽章激励机制
|
||||
- 查看课程信息,下载课程资料
|
||||
- 知识点检测及针对性训练
|
||||
- 在线作业,考试
|
||||
- 在线答疑,向老师或者学生提问
|
||||
|
||||
管理端:
|
||||
|
||||
- 课程管理,用户管理(需要管理员权限)
|
||||
- 课程信息管理
|
||||
- 课程公告管理
|
||||
- 题库管理,支持单选,多选,填空,编程题,支持题目编组
|
||||
- 发布作业,包括个性组题和手动组题
|
||||
- 发布考试,包括随机出题和手动出题
|
||||
- 自动判题,支持编程题判重
|
||||
- 在线答疑,给学生解答
|
||||
- 统计分析,包含测试统计和课程统计
|
||||
|
||||
洋洋洒洒需求列了一大堆,后面才发现是给自己挖坑,,答辩老师一看这类的题目就不感兴趣了,不论你做的咋样(况且我的演讲能力真的很一般),最后累死累活写了一大堆功能也没太高的分,,不过倒是让我的系统设计能力和代码能力有了不少的提高。
|
||||
|
||||
<!-- more -->
|
||||
|
||||
## 2、架构选择
|
||||
|
||||
  大三的时候了解到 Node.js 这个比较“奇葩"的异步语言,再加上在公司实习了三个月也是用的 node 开发,对 node 已经比较熟悉了,于是就用它做了后台,前端用最近比较火的 vue.js 做单页应用。当时还想着负载均衡啥的,就没有用传统的 session,cookie 机制,转而用 jwt 做的基于 token 的身份认证,同时后台接口也是类 Restful 风格的(因为纯正的 Rest 接口太难设计了)。
|
||||
|
||||
总的来说后台用了以下技术和框架:
|
||||
|
||||
  总的来说后台用了以下技术和框架:
|
||||
|
||||
- 语言:Node.js
|
||||
- web 框架:kOA
|
||||
- 前后台传输协议:jwt
|
||||
- 缓存:redis
|
||||
- 数据库:mysql
|
||||
- 编程题判题核心:[青岛大学 OJ 判题核心](https://github.com/QingdaoU/JudgeServer)
|
||||
- 代码判重:[SIM](https://dickgrune.com/Programs/similarity_tester/)
|
||||
|
||||
前台技术如下:
|
||||
|
||||
- 框架:Vue.js
|
||||
- UI 框架:Element-UI
|
||||
- 图表组件:G2
|
||||
|
||||
## 3、系统基础框架搭建
|
||||
|
||||
  本系统是前后端分离的,下面分别介绍前后端的实现基础。
|
||||
|
||||
### 1、后台
|
||||
|
||||
  一个 web 后台最重要的无非那么几个部分:路由;权限验证;数据持久化。
|
||||
|
||||
#### a、路由
|
||||
|
||||
KOA 作为一个 web 框架其实它本身并没有提供路由功能,需要配合使用 koa-router 来实现路由,koa-router 以类似下面这样的风格来进行路由:
|
||||
|
||||
  KOA 作为一个 web 框架其实它本身并没有提供路由功能,需要配合使用 koa-router 来实现路由,koa-router 以类似下面这样的风格来进行路由:
|
||||
|
||||
```javascript
|
||||
const app = require('koa');
|
||||
const router = require('koa-router');
|
||||
router.get('/hello', koa => {
|
||||
koa.response = 'hello';
|
||||
});
|
||||
app.use(router.routes());
|
||||
```
|
||||
|
||||
显然这样在项目中是很不方便的,如果每个路由都要手动进行挂载,很难将每个文件中的路由都挂载到一个 router 中。因此在参考网上的实现后,我写了一个方法在启动时自动扫描某个文件夹下所有的路由文件并挂载到 router 中,代码如下:
|
||||
|
||||
```javascript
|
||||
const fs = require('fs');
|
||||
const path = require('path');
|
||||
const koaBody = require('koa-body');
|
||||
const config = require('../config/config.js');
|
||||
|
||||
function addMapping(router, filePath) {
|
||||
let mapping = require(filePath);
|
||||
for (let url in mapping) {
|
||||
if (url.startsWith('GET ')) {
|
||||
let temp = url.substring(4);
|
||||
router.get(temp, mapping[url]);
|
||||
console.log(`----GET:${temp}`);
|
||||
} else if (url.startsWith('POST ')) {
|
||||
let temp = url.substring(5);
|
||||
router.post(temp, mapping[url]);
|
||||
console.log(`----POST:${temp}`);
|
||||
} else if (url.startsWith('PUT ')) {
|
||||
let temp = url.substring(4);
|
||||
router.put(temp, mapping[url]);
|
||||
console.log(`----PUT:${temp}`);
|
||||
} else if (url.startsWith('DELETE ')) {
|
||||
let temp = url.substring(7);
|
||||
router.delete(temp, mapping[url]);
|
||||
console.log(`----DELETE: ${temp}`);
|
||||
} else {
|
||||
console.log(`xxxxx无效路径:${url}`);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function addControllers(router, filePath) {
|
||||
let files = fs.readdirSync(filePath);
|
||||
files.forEach(element => {
|
||||
let temp = path.join(filePath, element);
|
||||
let state = fs.statSync(temp);
|
||||
if (state.isDirectory()) {
|
||||
addControllers(router, temp);
|
||||
} else {
|
||||
if (!temp.endsWith('Helper.js')) {
|
||||
console.log('\n--开始处理: ' + element + '路由');
|
||||
addMapping(router, temp);
|
||||
}
|
||||
}
|
||||
});
|
||||
}
|
||||
|
||||
function engine(router, folder) {
|
||||
addControllers(router, folder);
|
||||
return router.routes();
|
||||
}
|
||||
|
||||
module.exports = engine;
|
||||
```
|
||||
|
||||
然后在 index.js 中 use 此方法:
|
||||
|
||||
```
|
||||
const RouterMW = require("./middleware/controllerEngine.js");
|
||||
app.use(RouterMW(router,path.join(config.rootPath, 'api')));
|
||||
```
|
||||
|
||||
然后路由文件以下面的形式编写:
|
||||
|
||||
```javascript
|
||||
const knowledgePointDao = require('../dao/knowledgePointDao.js');
|
||||
|
||||
/**
|
||||
* 返回某门课的全部知识点,按章节分类
|
||||
*/
|
||||
exports['GET /course/:c_id/knowledge_point'] = async (ctx, next) => {
|
||||
let res = await knowledgePointDao.getPontsOrderBySection(ctx.params.c_id);
|
||||
ctx.onSuccess(res);
|
||||
};
|
||||
|
||||
//返回某位学生知识点答题情况
|
||||
exports['GET /user/:u_id/course/:c_id/knowledge_point/condition'] = async (
|
||||
ctx,
|
||||
next
|
||||
) => {
|
||||
let { u_id, c_id } = ctx.params;
|
||||
let res = await knowledgePointDao.getStudentCondition(u_id, c_id);
|
||||
ctx.onSuccess(res);
|
||||
};
|
||||
```
|
||||
|
||||
#### b、权限验证
|
||||
|
||||
  权限管理是一个系统最重要的部分之一,目前主流的方式为**基于角色的权限管理**, 一个用户对应多个角色,每个角色对应多个权限(本系统中每个用户对应一个身份,每个身份对应多个角色)。我们的系统如何实现的呢?先从登录开始说起,本系统抛弃了传统的 cookie,session 模式,使用 json web token(JWT)来做身份认证,用户登录后返回一个 token 给客户端,代码如下所示:
|
||||
|
||||
```javascript
|
||||
//生成随机盐值
|
||||
let str = StringHelper.getRandomString(0, 10);
|
||||
//使用该盐值生成token
|
||||
let token = jwt.sign(
|
||||
{
|
||||
u_id: userInfo.u_id,
|
||||
isRememberMe
|
||||
},
|
||||
str,
|
||||
{
|
||||
expiresIn: isRememberMe
|
||||
? config.longTokenExpiration
|
||||
: config.shortTokenExpiration
|
||||
}
|
||||
);
|
||||
//token-盐值存入redis,如想让该token过期,redis中清楚该token键值对即可
|
||||
await RedisHelper.setString(token, str, 30 * 24 * 60 * 60);
|
||||
res.code = 1;
|
||||
res.info = '登录成功';
|
||||
res.data = {
|
||||
u_type: userInfo.u_type,
|
||||
u_id: userInfo.u_id,
|
||||
token
|
||||
};
|
||||
```
|
||||
|
||||
以后每次客户端请求都要在 header 中设置该 token,然后每次服务端收到请求都先验证是否拥有权限,验证代码使用`router.use(auth)`,挂载到 koa-router 中,这样每次在进入具体的路由前都要先执行 auth 方法进行权限验证,主要验证代码逻辑如下:
|
||||
|
||||
```javascript
|
||||
/**
|
||||
* 1 验证成功
|
||||
* 2 登录信息无效 401
|
||||
* 3 已登录,无操作权限 403
|
||||
* 4 token已过期
|
||||
*/
|
||||
let verify = async ctx => {
|
||||
let token = ctx.headers.authorization;
|
||||
if (typeof token != 'string') {
|
||||
return 2;
|
||||
}
|
||||
let yan = await redisHelper.getString(token);
|
||||
if (yan == null) {
|
||||
return 2;
|
||||
}
|
||||
let data;
|
||||
try {
|
||||
data = jwt.verify(token, yan);
|
||||
} catch (e) {
|
||||
return 2;
|
||||
}
|
||||
if (data.exp * 1000 < Date.now()) {
|
||||
return 4;
|
||||
}
|
||||
//判断是否需要刷新token,如需要刷新将新token写入响应头
|
||||
if (!data.isRememberMe && data.exp * 1000 - Date.now() < 30 * 60 * 1000) {
|
||||
//token有效期不足半小时,重新签发新token给客户端
|
||||
let newYan = StringHelper.getRandomString(0, 10);
|
||||
let newToken = jwt.sign(
|
||||
{
|
||||
u_id: data.u_id,
|
||||
isRememberMe: false
|
||||
},
|
||||
newYan,
|
||||
{
|
||||
expiresIn: config.shortTokenExpiration
|
||||
}
|
||||
);
|
||||
// await redisHelper.deleteKey(token);
|
||||
await redisHelper.setString(newToken, newYan, config.shortTokenExpiration);
|
||||
ctx.response.set('new-token', newToken);
|
||||
ctx.response.set('Access-Control-Expose-Headers', 'new-token');
|
||||
}
|
||||
//获取用户信息
|
||||
let userInfoKey = data.u_id + '_userInfo';
|
||||
let userInfo = await redisHelper.getString(userInfoKey);
|
||||
if (userInfo == null || Object.keys(userInfo).length != 3) {
|
||||
userInfo = await mysqlHelper.first(
|
||||
`select u_id,u_type,j_id from user where u_id=?`,
|
||||
data.u_id
|
||||
);
|
||||
await redisHelper.setString(
|
||||
userInfoKey,
|
||||
JSON.stringify(userInfo),
|
||||
24 * 60 * 60
|
||||
);
|
||||
} else {
|
||||
userInfo = JSON.parse(userInfo);
|
||||
}
|
||||
ctx.userInfo = userInfo;
|
||||
//更新用户上次访问时间
|
||||
mysqlHelper.execute(
|
||||
`update user set last_login_time=? where u_id=?`,
|
||||
Date.now(),
|
||||
userInfo.u_id
|
||||
);
|
||||
//管理员拥有全部权限
|
||||
if (userInfo.u_type == 0) {
|
||||
return 1;
|
||||
}
|
||||
//获取该用户类型权限
|
||||
let authKey = userInfo.j_id + '_authority';
|
||||
let urls = await redisHelper.getObject(authKey);
|
||||
// let urls = null;
|
||||
if (urls == null) {
|
||||
urls = await mysqlHelper.row(
|
||||
`
|
||||
select b.r_id,b.url,b.method from jurisdiction_resource a inner join resource b on a.r_id = b.r_id where a.j_id=?
|
||||
`,
|
||||
userInfo.j_id
|
||||
);
|
||||
let temp = {};
|
||||
urls.forEach(item => {
|
||||
temp[item.url + item.method] = true;
|
||||
});
|
||||
await redisHelper.setObject(authKey, temp);
|
||||
urls = temp;
|
||||
}
|
||||
//判断是否拥有权限
|
||||
if (
|
||||
urls.hasOwnProperty(
|
||||
ctx._matchedRoute.replace(config.url_prefix, '') + ctx.method
|
||||
)
|
||||
) {
|
||||
return 1;
|
||||
} else {
|
||||
return 3;
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
根据用户 id 获取用户身份 id,根据用户身份 id 从 redis 中获取拥有的权限,如为 null,从 mysql 数据库中拉取,并存入 redis 中,然后判断是否拥有要访问的 url 权限。
|
||||
|
||||
#### c、数据持久化
|
||||
|
||||
  本系统中使用 mysql 存储数据,redis 做缓存,由于当时操作库不支持 promise,故对它两做了个 promise 封装,方便代码中调用,参见:[MysqlHelper](https://github.com/FleyX/teach_system/tree/master/teachSystem/util/MysqlHelper.js),[RedisHelper.js](https://github.com/FleyX/teach_system/tree/master/teachSystem/util/RedisHelper.js)。
|
||||
|
||||
### 2、前端
|
||||
|
||||
  前端使用 vue-cli 构建 vue 项目,主要用到了 vue-router,element-ui,axios 这三个组件。
|
||||
|
||||
#### a、路由组织
|
||||
|
||||
  单页应用需要前端自己组织路由。本系统将路由分成了三个部分:公共,管理端,学生端。index.js 如下:
|
||||
|
||||
```javascript
|
||||
export default new Router({
|
||||
mode: 'history',
|
||||
base: '/app/',
|
||||
routes: [
|
||||
{
|
||||
path: '',
|
||||
name: 'indexPage',
|
||||
component: IndexPage
|
||||
},
|
||||
{
|
||||
path: '/about',
|
||||
name: 'about',
|
||||
component: About
|
||||
},
|
||||
Admin,
|
||||
Client,
|
||||
Public,
|
||||
{
|
||||
path: '*',
|
||||
name: 'NotFound',
|
||||
component: NotFound
|
||||
}
|
||||
]
|
||||
});
|
||||
```
|
||||
|
||||
其中的 Admin,Client,Public 分别为各部分的路由,以子路由的形式一级级组织。如下所示:
|
||||
|
||||
```javascript
|
||||
export default {
|
||||
path: "/client",
|
||||
component: Client,
|
||||
beforeEnter: (to, from, next) => {
|
||||
if (getClientUserInfo() == null) {
|
||||
next({
|
||||
path: '/public/client_login',
|
||||
replace: true,
|
||||
})
|
||||
} else {
|
||||
next();
|
||||
}
|
||||
},
|
||||
children: [{
|
||||
//学生端主页
|
||||
path: '',
|
||||
name: "ClientMain",
|
||||
component: ClientHome
|
||||
}, {
|
||||
//学生个人资料页面
|
||||
path: 'person/student_info',
|
||||
name: "StudentInfo",
|
||||
component: StudentInfo
|
||||
}, {
|
||||
//公告页面
|
||||
path: 'course/:c_id/announcement',
|
||||
name: 'Main',
|
||||
component: Announcement
|
||||
}, {
|
||||
//课程基本信息
|
||||
path: 'course/:c_id/base',
|
||||
component: ClientMain,
|
||||
children: [{
|
||||
path: 'course_intro',
|
||||
name: "ClientCourseIntro",
|
||||
component: CourseIntro
|
||||
}, {
|
||||
path: 'exam_type',
|
||||
name: "ClientExamType",
|
||||
component: ExamType
|
||||
}
|
||||
......
|
||||
```
|
||||
|
||||
其中的 beforEnter 为钩子函数,每次进入路由时执行该函数,用于判断用户是否登录。这里涉及到了一个前端鉴权的概念,由于前后端分离了,前端也必须做鉴权以免用户进入到了无权限的页面,这里我只是简单的做了登录判断,更详细的 url 鉴权也可实现,只需在对应的钩子函数中进行鉴权操作,更多关于钩子函数信息[点击这里](https://router.vuejs.org/zh/guide/advanced/navigation-guards.html)。
|
||||
|
||||
#### b、请求封装
|
||||
|
||||
  前端还有一个比较重要的部分是 ajax 请求的处理,请求处理还保护错误处理,有些错误只需要统一处理,而有些又需要独立的处理,这样一来就需要根据业务需求进行一下请求封装了,对结果进行处理后再返回给调用者。我的实现思路是发起请求,收到响应后先对错误进行一个同意弹窗提示,然后再将错误继续向后传递,调用者可选择性的捕获错误进行针对性处理,主要代码如下:
|
||||
|
||||
```javascript
|
||||
request = (url, method, params, form, isFormData, type) => {
|
||||
let token;
|
||||
if (type == 'admin') token = getToken();
|
||||
else token = getClientToken();
|
||||
let headers = {
|
||||
Authorization: token
|
||||
};
|
||||
if (isFormData) {
|
||||
headers['Content-Type'] = 'multipart/form-data';
|
||||
}
|
||||
return new Promise((resolve, reject) => {
|
||||
axios({
|
||||
url,
|
||||
method,
|
||||
params,
|
||||
data: form,
|
||||
headers
|
||||
// timeout:2000
|
||||
})
|
||||
.then(res => {
|
||||
resolve(res.data);
|
||||
//检查是否有更新token
|
||||
// console.log(res);
|
||||
if (res.headers['new-token'] != undefined) {
|
||||
console.log('set new token');
|
||||
if (vm.$route.path.startsWith('/admin')) {
|
||||
localStorage.setItem('token', res.headers['new-token']);
|
||||
window.token = undefined;
|
||||
} else if (vm.$route.path.startsWith('/client')) {
|
||||
localStorage.setItem('clientToken', res.headers['new-token']);
|
||||
window.clientToken = undefined;
|
||||
}
|
||||
}
|
||||
})
|
||||
.catch(err => {
|
||||
reject(err);
|
||||
if (err.code == 'ECONNABORTED') {
|
||||
alertNotify('错误', '请求超时', 'error');
|
||||
return;
|
||||
}
|
||||
if (err.message == 'Network Error') {
|
||||
alertNotify('错误', '无法连接服务器', 'error');
|
||||
return;
|
||||
}
|
||||
if (err.response != undefined) {
|
||||
switch (err.response.status) {
|
||||
case 401:
|
||||
if (window.isGoToLogin) {
|
||||
return;
|
||||
}
|
||||
//使用该变量表示是否已经弹窗提示了,避免大量未登录弹窗堆积。
|
||||
window.isGoToLogin = true;
|
||||
vm.$alert(err.response.data, '警告', {
|
||||
type: 'warning',
|
||||
showClose: false
|
||||
}).then(res => {
|
||||
window.isGoToLogin = false;
|
||||
if (vm.$route.path.startsWith('/admin/')) {
|
||||
clearInfo();
|
||||
vm.$router.replace('/public/admin_login');
|
||||
} else {
|
||||
clearClientInfo();
|
||||
vm.$router.replace('/public/client_login');
|
||||
}
|
||||
});
|
||||
break;
|
||||
case 403:
|
||||
alertNotify(
|
||||
'Error:403',
|
||||
'拒绝执行:' + err.response.data,
|
||||
'error'
|
||||
);
|
||||
break;
|
||||
case 404:
|
||||
alertNotify(
|
||||
'Error:404',
|
||||
'找不到资源:' + url.substr(0, url.indexOf('?')),
|
||||
'error'
|
||||
);
|
||||
break;
|
||||
case 400:
|
||||
alertNotify(
|
||||
'Error:400',
|
||||
'请求参数错误:' + err.response.data,
|
||||
'error'
|
||||
);
|
||||
break;
|
||||
case 500:
|
||||
alertNotify(
|
||||
'Error:500',
|
||||
'服务器内部错误:' + err.response.data,
|
||||
'error'
|
||||
);
|
||||
default:
|
||||
console.log('存在错误未处理:' + err);
|
||||
}
|
||||
} else {
|
||||
console.log(err);
|
||||
}
|
||||
});
|
||||
});
|
||||
};
|
||||
```
|
||||
|
||||
  到这里就算是简单介绍完了,,想要更加深入了解的可以去 github 查看源代码,地址如下:[https://github.com/FleyX/teach_system,](https://github.com/FleyX/teach_system)记得 star 哦!
|
||||
@ -1,28 +0,0 @@
|
||||
---
|
||||
id: "2018-09-20-10-58"
|
||||
date: "2018/09/20 10:58"
|
||||
title: "git crlf、lf自动转换问题"
|
||||
tags: ["git","crlf","lf","flyway"]
|
||||
categories:
|
||||
- "其他"
|
||||
- "踩坑"
|
||||
---
|
||||
|
||||
  项目组最近加了一个新功能到代码中,使用 flyway 记录数据库版本变更,该工具会记录每次数据库结构的修改并生成 sql 文件存在指定目录上(当然必须用它来变更数据库,外部的变更它是无法感知的),然后每次启动时 flyway 会检查使用的数据库和当前项目代码中的 sql 变更版本是否一致,一致正常启动,不一致中如果是数据库落后将会更新数据库(这样能够保证代码在任何地方运行数据库都是一致的),否则就报错了。数据库中有一张表记录版本信息,如下图:
|
||||
|
||||

|
||||
|
||||
同时本地代码中也有一个文件夹保存每次操作的 sql 语句,如下图:
|
||||
|
||||
|
||||
|
||||
通过对比 checksum 值来判断当前 sql 语句和生成数据库的执行语句是否一致,checksum 值由 CRC32 计算后处理得出。
|
||||
|
||||
  然后问题就来了,组中的其他人搭建好 flyway 后,项目文件生成了两个 sql 文件,我用 git 拉下来后启动报错,checkupsum 值对不上,,然后我又不懂这个 flyway 完全不知道咋回事,然后就根据报错的位置一点点找到 checkup 值生成的代码,发现是 CRC32 计算的,,(就这么搞了一两个小时才发现是文件不一致了),但是都是从 git 拉的怎么就我不一致呢???想到可能是文件换行符的问题,遂把那几个 sql 文件的文件换行符全换成了 crlf(windows 中的换行符),然后居然就能够运行。。。关于为啥都从 git 拉取的文件换行符会不一样原因是:他们都用的那个小乌龟的可视化,我用的命令行。可视化工具自动配置了文件换行符的自动转换(这是 git 的一个智能功能,上传时将文件换行符替换为 lf,,拉取时再替换为 crlf,,这样保证中心仓库使用 UNIX 风格的换行符,,本地能够根据运行环境使用相对应的换行符风格),但是命令行并没有配置。
|
||||
|
||||
  解决办法也很简单,开启 git 的自动转换。
|
||||
|
||||
```
|
||||
git config --global core.autocrlf true //开启换行符自动转换
|
||||
git config --global core.safecrlf true //禁止混用换行符
|
||||
```
|
||||
Loading…
x
Reference in New Issue
Block a user