diff --git a/java/springcloud实战/5.springCloud之Spring Cloud Stream事件驱动架构.md b/java/springcloud实战/5.springCloud之Spring Cloud Stream事件驱动架构.md
index 89f1704..89fe4f8 100644
--- a/java/springcloud实战/5.springCloud之Spring Cloud Stream事件驱动架构.md
+++ b/java/springcloud实战/5.springCloud之Spring Cloud Stream事件驱动架构.md
@@ -7,15 +7,15 @@ category="java"
serie="springCloud实战"
---
- 想想平常生活中做饭的场景,在用电饭锅做饭的同时,我们可以洗菜、切菜,等待电饭锅发出饭做好的提示我们回去拔下电饭锅电源(或者什么也不知让它处于保温状态),反正这个时候我们知道饭做好了,接下来可以炒菜了。从这里可以看出我们在日常生活中与世界的互动并不是同步的、线性的,不是简单的请求--响应模型。它是事件驱动的,我们不断的发送消息、接受消息、处理消息。
+ 想想平常生活中做饭的场景,在用电饭锅做饭的同时,我们可以洗菜、切菜,等待电饭锅发出饭做好的提示我们回去拔下电饭锅电源(或者什么也不知让它处于保温状态),反正这个时候我们知道饭做好了,接下来可以炒菜了。从这里可以看出我们在日常生活中与世界的互动并不是同步的、线性的,不是简单的请求--响应模型。它是事件驱动的,我们不断的发送消息、接受消息、处理消息。
同样在软件世界中也不全是请求--响应模型,也会需要进行异步的消息通信。使用消息实现事件通信的概念被称为消息驱动架构(Event Driven Architecture,EDA),也被称为消息驱动架构(Message Driven Architecture,MDA)。使用这类架构可以构建高度解耦的系统,该系统能够对变化做出响应,且不需要与特定的库或者服务紧密耦合。
- 在Spring Cloud项目中可以使用**Spirng Cloud Stream**轻而易举的构建基于消息传递的解决方案。
+ 在 Spring Cloud 项目中可以使用**Spirng Cloud Stream**轻而易举的构建基于消息传递的解决方案。
-# 1、为什么使用消息传递
+# 为什么使用消息传递
- 要解答这个问题,让我们从一个例子开始,之前一直使用的两个服务:许可证服务和组织服务。每次对许可证服务进行请求,许可证服务都要通过http请求到组织服务上查询组织信息。显而易见这次额外的http请求会花费较长的时间。如果能够将缓存组织数据的读操作,将会大幅提高许可证服务的响应时间。但是缓存数据有如下3个要求:
+ 要解答这个问题,让我们从一个例子开始,之前一直使用的两个服务:许可证服务和组织服务。每次对许可证服务进行请求,许可证服务都要通过 http 请求到组织服务上查询组织信息。显而易见这次额外的 http 请求会花费较长的时间。如果能够将缓存组织数据的读操作,将会大幅提高许可证服务的响应时间。但是缓存数据有如下 2 个要求:
- **缓存的数据需要在许可证服务的所有实例之间保存一致**——这意味着不能将数据缓存到服务实例的内存中。
- **在更新或者删除一个组织数据时,许可证服务缓存的数据需要失效**——避免读取到过期数据,需要尽早让过时数据失效并删除。
@@ -26,7 +26,54 @@ serie="springCloud实战"
2. 使用事件驱动。组织服务发出一个异步消息。许可证服务收到该消息后清除对应的缓存。
+## 同步请求-响应方式
-## 1.1、同步请求-响应方式
+ 许可证服务在 redis 中缓存从组织服务中查询到的服务信息,当组织数据更新时,组织服务同步 http 请求通知许可证服务数据过期。这种方式有以下几个问题:
- 对于组织服务的缓存使用Redis来进行存储。下图展示了传统的同步请求--响应来构建的缓存。
+- 组织服务和许可证服务紧密耦合
+- 这种方式不够灵活,如果要为组织服务添加新的消费者,必须修改组织服务代码,以让其通知新的服务数据变动。
+
+## 使用消息传递方式
+
+ 同样的许可证服务在 redis 中缓存从组织服务中查询到的服务信息,当组织数据更新时,组织服务将更新信息写入到队列中。许可证服务监听消息队列。使用消息传递有一下 4 个好处:
+
+- 松耦合性:将服务间的依赖,变成了服务对队列的依赖,依赖关系变弱了。
+- 耐久性:即使服务消费者已经关闭了,也可以继续往里发送消息,等消费者开启后处理
+- 可伸缩性: 消息发送者不用等待消息消费者的响应,它们可以继续做各自的工作
+- 灵活性:消息发送者不用知道谁会消费这个消息,因此在有新的消息消费者时无需修改消息发送代码
+
+# spring cloud 中使用消息传递
+
+ spring cloud 项目中可以通过 spring cloud stream 框架来轻松集成消息传递。该框架最大的特点是抽象了消息传递平台的细节,因此可以在支持的消息队列中随意切换(包括 Apache Kafka 和 RabbitMQ)。
+
+## spring cloud stream架构
+
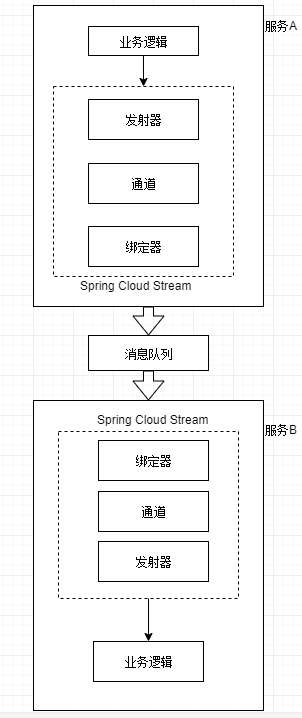
+ spring cloud stream中有4个组件涉及到消息发布和消息消费,分别为:
+
+1. 发射器
+ 当一个服务准备发送消息时,它将使用发射器发布消息。发射器是一个Spring注解接口,它接收一个普通Java对象,表示要发布的消息。发射器接收消息,然后序列化(默认序列化为JSON)后发布到通道中。
+
+2. 通道
+ 通道是对队列的一个抽象。通道名称是与目标队列名称相关联的。但是队列名称并不会直接公开在代码中,代码永远只会使用通道名。
+
+3. 绑定器
+ 绑定器是spring cloud stream框架的一部分,它是与特定消息平台对话的Spring代码。通过绑定器,使得开发人员不必依赖于特定平台的库和API来发布和消费消息。
+
+4. 接收器
+ 服务通过接收器来从队列中接收消息,并将消息反序列化。
+
+处理逻辑如下:
+
+
+
+## 实战
+
+ 继续使用之前的项目,在许可证服务中缓存组织数据到redis中。
+
+### 建立redis服务
+
+ 为方便起见,使用docker创建redis,建立脚本如下:
+
+```bash
+docker run -itd --name redis -p
+```
\ No newline at end of file
diff --git a/java/springcloud实战/file/spring-cloud-stream架构.xml b/java/springcloud实战/file/spring-cloud-stream架构.xml
new file mode 100644
index 0000000..81cb1f8
--- /dev/null
+++ b/java/springcloud实战/file/spring-cloud-stream架构.xml
@@ -0,0 +1 @@
+5Vpbk9MgGP01POqEkKTJY9JmdRwdL3XG1Tds2Caalg6htvXXCwlJGmDtutub+rILH7dwvsPHAQrQeLF9wfAqf0MzUgLXybYATYDrRl4g/krDrjEEUdgY5qzIGhPsDdPiJ1FGR1nXRUaqQUVOacmL1dA4o8slmfGBDTNGN8Nqd7QcjrrCc2IYpjNcmtZPRcbzxoqQ4/QFL0kxz9XQoihqSha4ra2qVjnO6GbPhFKAxoxS3qQW2zEpJXgtME27m3tKuy9jZMkf0mD3/evNq/QWf6neh5++fXhLg5fZs/bjfuByraYM0gAkAQhDmQghiG9AGgHht0gkfGmPRmpGfNfixOh6mRE5kgNQsskLTqYrPJOlG0EMYcv5ohQ5KJJqSMI42d47GdhBJLhF6IJwthNVVAPP95smilcoUBPZ9F6C7eTyPQch1Q4rYsy7rnvoREKh9ydIQhNJHSVBgZVM3pVkG0t2CjDIMlPJyazEVVXMhmCRbcFvJa7PfZX7vFcy2SrI68xOZZqBSWZwW4NXfBxdsxn5zbSUqzlmc8IPEsn0154/fIs7WhsjJebFj+H32nykRnhHCzGTjg5u635FB89zhl0081St9heJ1hGCw45QpHXUAGF0VFOmm/YTWOReD4sEV9hur5HMft4v65vVuROwr13BB+kXXZJ9I6SxDz6Sfb6rRbXRedk3Oky+swd6R1uQZpzvbIM47/zGjU8K9MGRQcpwldd1j4WYO0QMQmhujaEFMqjHuuPtjciASIaHqcpSxnM6p0tcpr01GYK4H8seGZe+Ec53SmLiNafC1I/8mtLVwAdHiV+tZD0UvgK7Rx8cl57kHYtwST2QCJ0X14IvBjGUElBwJklAGoIkBRE0PHppCehbaA4tNHejE+GILDgK+G4kWCKROCD0ZCKKQBxeHXzQ9R6Gny6tjoafZ8GvZp3kYSSPIpEZRy4OWxheGDbfAttIrtSGdnGq1vF10u7By/Zk+IUW/AIQjUE46cJfbOAmEOBDcBipip/4a11BYrmSKq3+WD8B/kRY5KZTNfuPbIDLYr4U6ZLcya4krMUMl7Eyc7khJZVwRrGcf6x3J7FEjuKEwBCshg9sctk9lQugKTynKyamLWzjkq4z8X/KGcGLf8sPnqfpfceyGGzq9mSeiMzFcPGIoZ0AvPaQdPAIoB/DjsdXy63ZlZ0BhsTy/MAklvUMEIxOhdnfKjO1q6UgsEB51g0LWu6IrlloBppOvzyANqV+fUpTxw1eHDebQr9iqakB2OUvB6BNq+taMzGA+6s1jqE1PdML5xWb5gXe/yE2A3foCGRZDmcVm64lnuiQ/6MPG23YOXgzCO9x6nleNpC2eLuXjj9+Vws1FRVqHT36ZUNk+zf0pnr/SwSU/gI=
\ No newline at end of file