diff --git a/数据库/分库分表/sharding-jdbc分库分表.md b/数据库/分库分表/sharding-jdbc分库分表.md
new file mode 100644
index 0000000..6bbb23c
--- /dev/null
+++ b/数据库/分库分表/sharding-jdbc分库分表.md
@@ -0,0 +1,230 @@
+---
+id: '2019-03-20-10-38'
+date: '2019/03/20 10:38:00'
+title: '超详细sharding-jdbc分库分表实现(基于spring-boot)'
+tags: ['springboot', '数据库', 'sharding-jdbc', 'XA', 'incubator-shardingsphere']
+categories:
+ - '数据库'
+ - '分库分表'
+---
+
+
+
+**demo 地址:**[https://github.com/FleyX/demo-project/tree/master/spring-boot/sjdemo](https://github.com/FleyX/demo-project/tree/master/spring-boot/sjdemo)
+
+**部分内容参考 ShardingSphere 官方文档:**[官方文档](https://shardingsphere.apache.org/document/current/cn/overview/)
+
+ 最近工作任务比较轻,又到了充电时间,所以就花了几天来研究分库分表相关的。呕心沥血输出了这篇博文和一个 demo 项目,基本涵盖了一般的分库分表场景。
+
+# 背景
+
+ 传统应用通常将数据集中存储在单一的数据节点中,已经越来越不能满足现代互联网的海量数据场景。随着用于用户的增长,对并发性能要求越来越高,系统后台服务可以很容易的进行扩容(负载均衡等),这样最终的瓶颈就是数据库了,单一的数据节点或者简单的主从结构是难以承受的。
+
+ 尽管目前已经有 nosql/newsql 能够支撑海量的数据,但是其对传统 sql 是不兼容的,而且生态圈页不太完善,关系型数据库的地位还是无法撼动的。
+
+ 由此产生了数据分片的概念。按照某个分片维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以提升性能。数据分片的拆分方式分为:垂直分片和水平分片两种。
+
+## 垂直分片
+
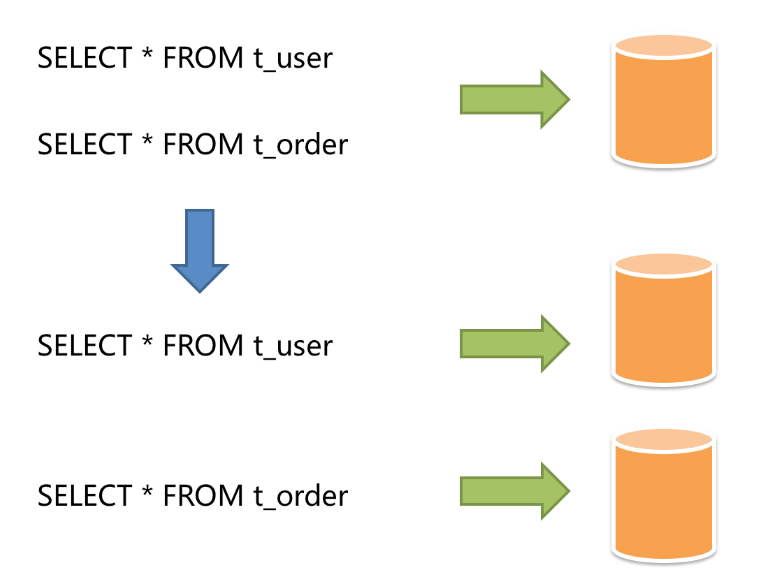
+ 按照业务逻辑拆分的方式称为垂直分片,又称为纵向拆分。核心理念就是专库专用。将一个大的数据库按照业务逻辑分类,拆分为多个小的数据库,每个业务逻辑使用各自的数据库,从而将压力分散到不同的数据库中。垂直分片往往需要对架构和设计进行调整,类似微服务的概念。但是垂直拆分只能属于一个治标不治本的办法,随着业务量进一步加大,超过了单个表能承受的阈值,还是会出现性能问题。然后就需要水平分片来进一步处理了。
+
+
+## 水平分片
+
+ 水平分片又称横向分片。相对于垂直分片,不根据业务逻辑分,而是通过某个(几个)字段,根据某种规则将数据分散到多个库或表中,每个分片仅包含数据的一部分。例如根据用户主键分片,对 2 取余为 0 的放入 0 库(或表),为 1 的放入 1 库(或表)。如下所示:
+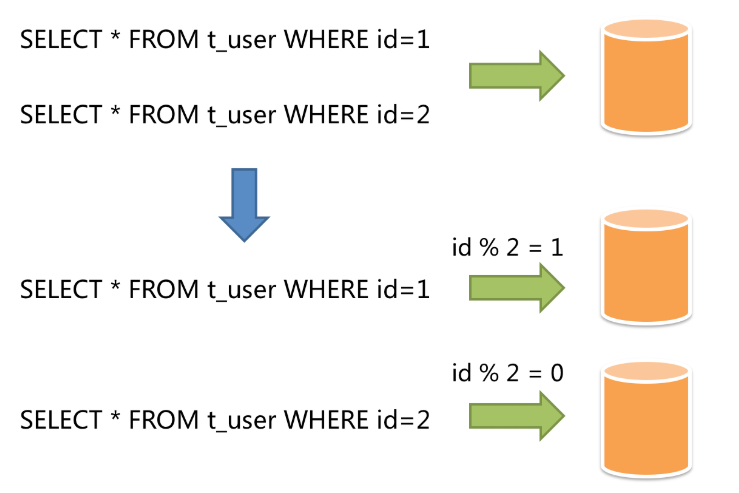
+从理论上来说水平分片是可以无限拓展的,属于分库分表的标准解决办法。
+
+ 但是有利就会有弊,虽然分片解决了性能问题,但是分布式的架构页引入了新的问题。
+
+ 首先面对的就是数据库的运维管理更加复杂,之前只是单库有限的几张表,现在数据被分散到了多库多表中,难以运维。
+
+ 其次就是很多之前能够正常运行的 sql 语句,在水平分片后无法正常运行,比如分页、排序、聚合分组等操作。
+
+ 最后就是分布式事务。跨库事务目前任然是一个较为棘手的事情。主要有两种解决办法:基于 XA 的分布式事务和最终一致性的柔性事务。
+
+# 实战
+
+ 了解了分库分表的概念下面就是实战了,最初是考虑使用 Mycat 的,但最终没有采用的原因主要是以下两点:
+
+- Mycat 较为混乱,没有明确的开发计划和完善的文档(文档是一本书)。而且首页看着像是 90 年代的页面。
+- 最关键的一点,Mycat 已经很久没有更新了,自从 17 年发布了最后一个版本就再没有动静了(官网说的是筹备 2.0 中)
+
+ 在查找资料的过程中了解到当当的一款开源分库分表产品--sharding-jdbc.目前已经迁移到 apache 孵化中心,首页也相应的换了,[现在的官网首页](https://shardingsphere.apache.org),同时也改名了:ShardingSphere。目前最新的发布版本是 3.1,有以下三个产品:
+
+- Sharding-JDBC。ShardingSphere 就是在此基础上发展来的。仅支持 java,属于轻量级 java 框架,在 java 的 JDBC 层提高额外服务,相当于加强版 JDBC 驱动,因此可以与任何上层 ORM 框架配合使用,支持任意的数据库连接池,支持任意实现 JDBC 规范的数据库。本篇代码就是基于 Sharding—JDBC。
+- Sharding-Proxy:跟 MyCat 一样属于数据库代理,对代码透明,目前仅支持 MySQL 数据库。
+- Sharding-Sidecar:规划中的产品,定位为云原生数据库代理。
+
+ 下面开始基于 Spring-boot 的实战。总体如下:
+
+- 分库分表使用
+- 广播表使用
+- 默认库使用
+
+(PS:官方也有使用示例:[https://github.com/apache/incubator-shardingsphere-example](https://github.com/apache/incubator-shardingsphere-example)
+
+## 建立数据表
+
+ 本例中共用到三个库四个表,如下:
+
+- ds0:
+ - user(分库不分表)
+ - order(分库分表)
+ - order_item(分库分表)
+ - dictionary(广播表,不分库不分表在,在所有库中都有相同的数据)
+- ds1:(同上)
+ - user
+ - order
+ - order_item
+ - dictionary
+- ds2:(默认数据库,除上面的表外其他的表)
+ - other_table
+
+建表语句在此:[https://github.com/FleyX/demo-project/tree/master/spring-boot/sjdemo/init](https://github.com/FleyX/demo-project/tree/master/spring-boot/sjdemo/init)
+
+## POM 依赖
+
+ springboot 主要依赖如下(完整依赖请在 github 中查看):
+
+```xml
+
+
+ mysql
+ mysql-connector-java
+ 5.1.24
+
+
+ io.shardingsphere
+ sharding-jdbc-spring-boot-starter
+ 3.1.0
+
+
+ com.alibaba
+ druid
+ 1.1.14
+
+
+
+ org.projectlombok
+ lombok
+
+
+
+ com.alibaba
+ fastjson
+ 1.2.56
+
+
+
+
+ io.shardingsphere
+ sharding-transaction-2pc-xa
+ 3.1.0
+
+
+
+ io.shardingsphere
+ sharding-transaction-spring-boot-starter
+ 3.1.0
+
+```
+
+## yaml 配置
+
+```yaml
+# application.yml
+spring:
+ profiles:
+ active: sharding
+mybatis:
+ mapper-locations: classpath:mapper/*.xml
+ type-aliases-package: com.fanxb.sjdemo.entity
+ # 开启mybatis sql打印
+ configuration:
+ log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
+```
+
+这里是关键,分库分表配置。需要将所有的表列出(包含广播表),未列出的表将使用默认库。
+需给所有配置了分库分表的数据表加上一个 userId 字段,因为要根据 userId 来判断写入到哪个库中,否则回向所有库插入。
+
+```yaml
+sharding:
+ jdbc:
+ datasource:
+ # 配置数据源
+ names: ds0,ds1,ds2
+ ds0:
+ type: com.alibaba.druid.pool.DruidDataSource
+ driver-class-name: com.mysql.jdbc.Driver
+ url: jdbc:mysql://10.82.27.177:3306/ds0
+ username: root
+ password: 123456
+ ds1:
+ type: com.alibaba.druid.pool.DruidDataSource
+ driver-class-name: com.mysql.jdbc.Driver
+ url: jdbc:mysql://10.82.27.177:3306/ds1
+ username: root
+ password: 123456
+ ds2:
+ type: com.alibaba.druid.pool.DruidDataSource
+ driver-class-name: com.mysql.jdbc.Driver
+ url: jdbc:mysql://10.82.27.177:3306/ds2
+ username: root
+ password: 123456
+ config:
+ sharding:
+ # 默认数据源,可以将不分库分表的数据表放在这里(此处的表需与已经分库分表的表完全没有关联,不会产生联表查询操作,因为跨库连表查询是没办法实现的)
+ # 3.1.0版本中dql查询存在bug,不使用默认库.会在下个版本中修复
+ default-data-source-name: ds2
+ # 默认分库策略,根据userId对2取余确定库
+ default-database-strategy:
+ inline:
+ sharding-column: userId
+ algorithm-expression: ds$->{userId % 2}
+ # 配置表策略
+ tables:
+ # 公共表(比如字典表,角色表,权限表等),不分库分表,数据将发送到所有库中,方便联表查询
+ dictionary:
+ # 配置主键,以便sharding-jdbc生成主键
+ key-generator-column-name: dictionaryId
+ actual-data-nodes: ds$->{0..1}.dictionary
+ # user 已经根据userId分库,因此user表不进行分表
+ user:
+ key-generator-column-name: userId
+ actual-data-nodes: ds$->{0..1}.user
+ order:
+ key-generator-column-name: orderId
+ actual-data-nodes: ds$->{0..1}.order$->{0..1}
+ table-strategy:
+ inline:
+ # 设置分片键,相同分片键的连表查询不会出现笛卡儿积
+ sharding-column: orderId
+ # 设置分表规则,根据订单id对2取余分两个表
+ algorithm-expression: order$->{orderId%2}
+ order_item:
+ key-generator-column-name: orderItemId
+ actual-data-nodes: ds$->{0..1}.order_item$->{0..1}
+ table-strategy:
+ inline:
+ sharding-column: orderId
+ # 设置分表规则,根据订单id对2取余分两个表
+ algorithm-expression: order_item$->{orderId%2}
+ # 打印sql解析过程
+ props:
+ sql.show: true
+```
+
+ 到这里就算配置完毕了,剩下的过程和普通 spring boot+mybatis 项目一样,不再赘述。
+
+## 事务处理
+
+ 默认使用的是本地事务,但是如果业务逻辑抛出错误,还是会对所有的库进行回退操作的,只是如果出现断电断网的情况会导致数据不一致。详见:[官方文档](https://shardingsphere.apache.org/document/current/cn/features/transaction/local-transaction/).
+
+ 可通过`@ShardingTransactionType(TransactionType.XA)`注解,切换为 XA 事务或者柔性事务(示例中未配置,切换为柔性事务会报错)。
+
+# 测试
+
+ 运行`com.fanxb.sjdemo.MainTest`查看测试结果。
+
+**本文原创发布于:**[https://www.tapme.top/blog/detail/2019-03-20-10-38](https://www.tapme.top/blog/detail/2019-03-20-10-38)